论文简介
本文收录于KDD18,来自于阿里妈妈的精准定向检索及基础算法团队。文章的创新点主要有三个:
- Deep Interest Network(DIN)—— 通过一个局部激活单元(local activation unit)来自适应地从用户历史行为中学习他对于某个广告的兴趣。
- Mini-batch Aware Regularization —— 即一个针对mini-batch SGD进行优化的L2 norm正则项,通过近似减少了计算量。
- 一个数据自适应的激活函数,对PReLU的indicator function进行修改,并取名为Dice。
下面具体分析一下这几个创新点。
网络结构
这篇论文的名字叫《Deep Interest Network for Click-Through Rate Prediction》,很显然,DIN是其中最重要的一个创新点。DIN要解决的一个问题是如何高效地捕获用户对于某个广告的兴趣。作者发现用户的兴趣有两个特点:一是通常很广泛(diverse),例如用户一般不会只对某一类商品感兴趣,而是会对多种商品感兴趣;二是只有用户的部分兴趣会影响到他点击某个广告与否。
第一个特点就导致现有的Embedding&MLP方法的一个大问题:无法用一个维度合适的向量表示某个用户的所有兴趣。在这些方法中,由于用户行为的embedding是一个固定长度的向量,因此一旦长度比较小,我们可能就无法捕捉到足够的表征用户兴趣的信息。而一旦长度太大,时间复杂度又无法接受。那么怎么解决呢?这里我们再看一下上面的第二个特点,也就是对于某个广告来说,只有用户的部分兴趣会影响其是否点击。既然统一表征所有兴趣需要的维度太大,而且我们实际上只需要用到部分兴趣,有没有办法针对性地得到对于某个广告来说会影响用户点击的部分兴趣呢?还真有,那就是Attention机制。
Attention最早用于机器翻译中进行对齐,后来其思想被泛化后也被用于其他的各种领域。在机器翻译中,最早的Encoder-Decoder模型中的Encoder实际上和我们这里的Embedding&MLP方法很像,就是将高维信息压缩为一个定长的低维向量。其问题也很类似,一个是定长向量的信息表示能力,另一个是机器翻译中原句的各个单词对译句的各个单词的影响力是不同的。为了解决这一问题,Bengio等人提出了Attention机制,即通过对比原句中各个词的embedding(准确的说是对应RNN或LSTM的隐藏层输出)和译句中某个词的embedding来计算出原句中各个词的影响权重,再通过加权求和的形式得到不同的中间语义(即Encoder的结果)。不同的中间语义会影响到Decoder输出的不同时刻的word embedding结果,即影响到最终的翻译结果。由于在得到译句中不同的词时我们对于原句中各个词的attention是不一样的,所以这个机制被称为Attention机制。此外,因为翻译中基本是单词对单词或者短语对短语,所以这也起到了一个对齐的作用。
回到广告点击率预估的场景,这里的用户行为embedding就类似于机器翻译中Encoder输出的中间语义,而不同的兴趣就对应于原句中不同的单词,某个广告就对应于译句中的某个单词。所以我们现在要做的也就是对比不同兴趣和当前广告,得到不同兴趣对应的影响权重,之后通过加权求和得到所有兴趣的总体影响。有了用户行为的embedding后,配合其他类型特征的embedding和广告的embedding,就可以训练一个DNN来得到预测结果了。
下面就是如何设计得到不同兴趣对应的影响权重了。原始数据中一般不会直接告诉你所谓的兴趣是什么,其更多的是通过分析用户对某个商品的行为来隐式地获取的。在这里,兴趣的embedding对应于各个商品的embedding(这里的商品更像是品类,其原始数据是一个one-hot或multi-hot编码,由于商品的编码长度固定,因此对于multi-hot来说,需要将其位置为1的各个embedding进行pooling),兴趣的影响权重也就转换为商品的影响权重。那么如何比较两个embedding来得到对应的权重呢?一般来说进行比较的两个向量的维度是相同的,所以常见的得到权重的方式包括向量内积、加权内积和训练一个新网络。我们来看一下DIN是怎么做的:
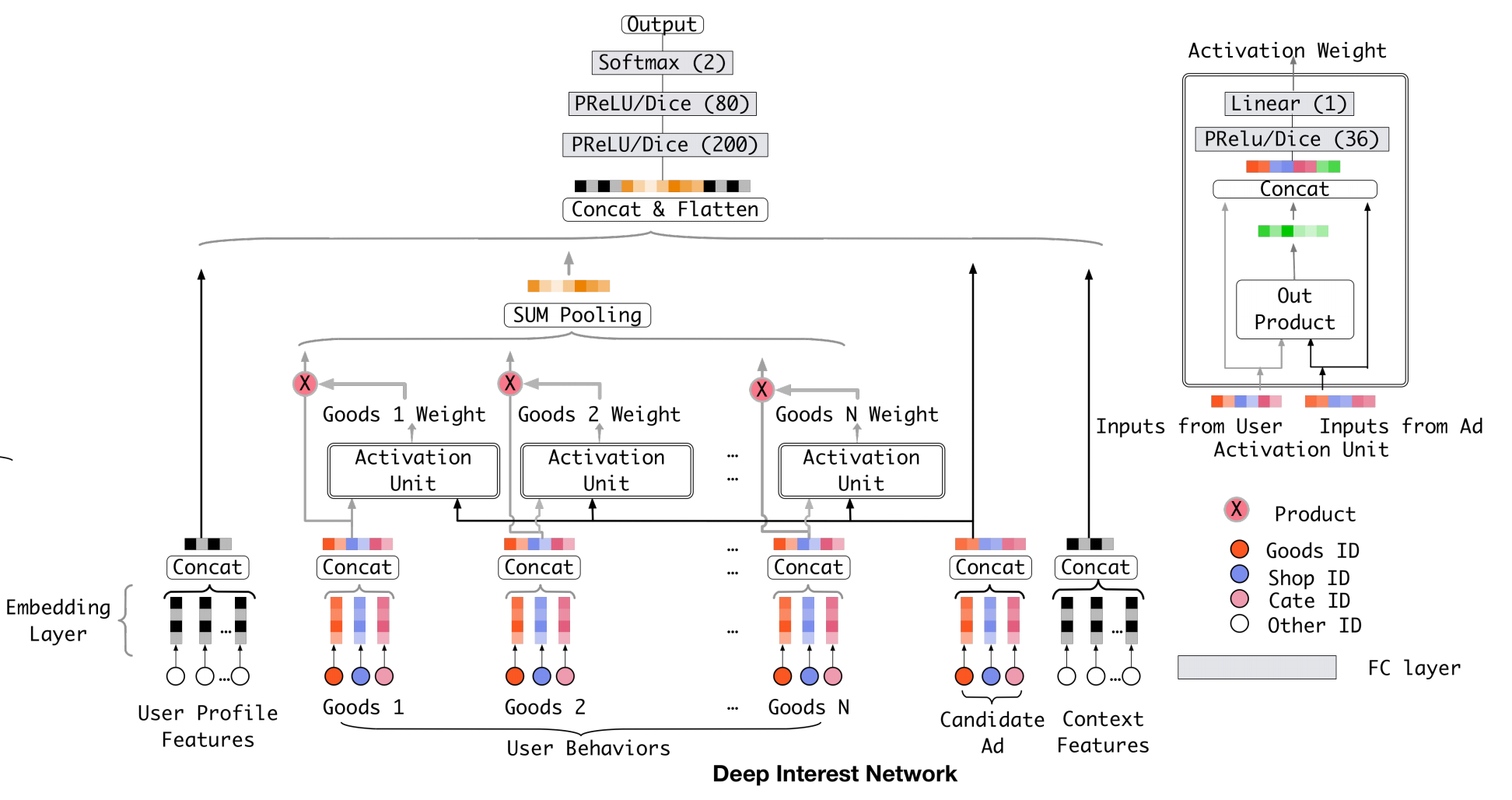
上面这张图是是DIN的网络结构。左边是它整体的一个结构,右边是激活单元的一个详细说明(这里的激活单元就是上文中说的得到权重的方式)。我们先看左边的整体结构。最下面是embedding层,将高维稀疏的原始数据映射为低维稠密向量。embedding后的特征分为四部分:用户画像特征,用户行为特征,广告特征和上下文特征,其中用户行为特征会通过激活单元以及sum pooling得到一个处理后的针对当前广告的总体兴趣向量(因为激活单元的输出是一个标量,所以这里其实就是对用户行为特征的加权求和)。将这四部分拼接后,通过两层全连接层和一层softmax就可以得到最后的概率值。
接下来我们聚焦到DIN中最重要的激活单元部分(这也是DIN和baseline的区别所在)。激活单元的输入是商品向量和广告向量,二者经过外积后再与原始向量进行拼接。拼接后的向量经过一个全连接层和一个加权叠加后得到一个标量w。外积+embedding拼接有点类似于FM的思想,构造所谓的“一阶”和“二阶交叉”特征,其实就是通过一种方式来在原始embedding之上构建一些行为和广告的交叉特征,再通过全连接层对信息进一步整合并得到对应的权重。文章中还提到这些权重没有进行归一化,而是直接与原embedding相乘,其累加和表示某种程度上的用户对于某个广告的总兴趣程度。也就是说,兴趣的总和并不固定为1,而是会随着广告的变化而变化。事实上也是如此,假如某人90%的购物用在电子产品上,那么他对电子产品相关的广告的总兴趣肯定是大于其他广告的,这可以理解为在更高的维度进行了某种加权,或者说将权重总和映射到一个实数空间。
Mini-batch Aware Regularization
一开始有提到,本文的第二个亮点在于提出一种针对mini-batch SGD进行l2 norm正则项近似的方法,从而使得用于计算正则项的时间减少。这里在计算某个embedding特征的l2 norm时,将其权重的分子部分由mini-batch的样本中该特质对应的原始特征不为0的次数近似为“是否出现过”,出现过就是1,否则是0。由于这一操作会将高频率出现的特征对应的正则项减小,那么反过来其实就是相当于把低频率出现的特征对应的正则项增大,从而解决用户行为数据中的长尾问题,防止对于尾部数据过拟合。
Dice
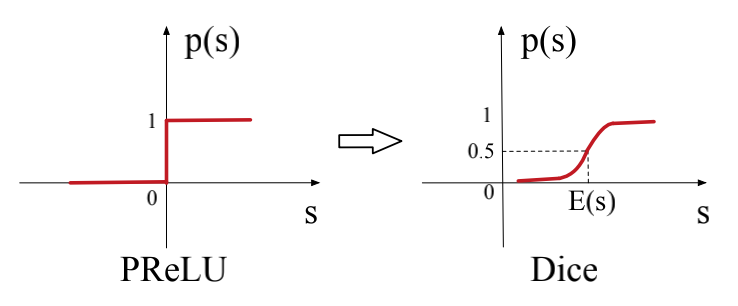
Dice对PReLU的indicator function进行修改,将其由位于0处的阶跃函数调整为一个自适应于数据均值和方差的平滑变化函数(类似于sigmoid的形状),两种indicator function的函数图如下所示(即图中的p(s)):
PReLU原本的形式是:
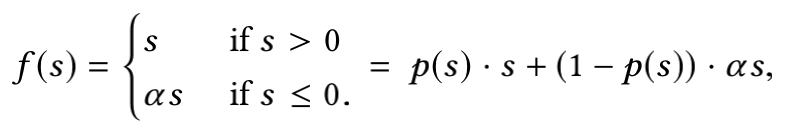
将indicator function改为Dice后变为:
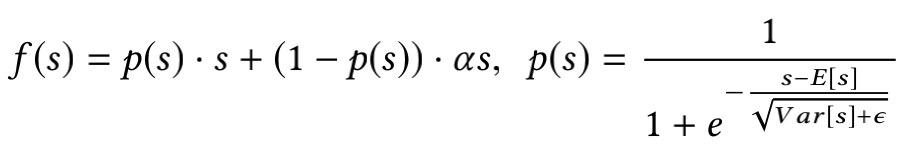
从p(s)的公式可以看出这其实是将s进行标准化后带入sigmoid函数。标准化的操作其实就是一种基于数据的自适应调整,而带入sigmoid函数的想法和谷歌提出的Swish不谋而合。Swish的形式为f(x) = x · sigmoid(βx),和不加入标准化的Dice很像,不过两者似乎都未给出这种形式的激活函数效果更好的原因说明。
总结
DIN将Attention思想结合进CTR预估场景的想法还是比较巧妙的,不仅解决了之前方法中用户行为embedding长度固定的问题,还考虑到了对于不同广告,用户的不同兴趣对于其是否点击的操作存在不同影响,个人认为是一篇很不错的文章。