论文简介
本文收录于AAAI2019,和DIN一样来自于阿里妈妈的精准定向检索及基础算法团队。从思路上来说,DIEN可以看做是DIN的一种扩展,不过具体的结构和实现还是改动比较大。DIEN主要想解决的问题是两个:一是如何更准确地得到兴趣的表示,二是如何捕获兴趣变化的过程。第一个问题可以理解为是DIN上不足的一个扩展,因为DIN其实比较简单的把用户行为看做是用户兴趣,但事实上兴趣很难由这些行为完全地表示出来,DIEN提出了一个兴趣抽取层(interest extractor layer)来解决这个问题。第二个问题是对于兴趣的一种完善,由于用户的兴趣是不停变换的,而且每个人的变化程度和时间(可以抽象为轨迹)都不同,因此如何对于某个特定的商品捕获与之相关的兴趣轨迹也是一个难点。DIEN提出了一个兴趣演变层(interest envolve layer)来解决这个问题。我们下面就来具体看看这两个layer的结构,以及为什么它们能解决上面说的两个问题。
网络结构
兴趣抽取层
兴趣抽取层做的就是从用户行为数据中抽取出用户兴趣。这里作者重点关注用户行为数据的两个特点:一是用户行为往往是一个序列,即存在先后顺序和相关性。处理序列相关的问题我们一般会采用RNN相关的模型,例如LSTM和GRU,这里作者选择的是GRU,因为它具有避免梯度消失和速度快的优点。第二个特点是某条数据的标签(这里就是是否点击某个广告)是由用户的最后时刻的兴趣决定的,但是由于用户的兴趣一直在变化,因此只用标签来训练整个兴趣轨迹是不够准确的,需要找到另外的标签来训练中间兴趣(即隐藏层的结果)。这里作者引入了辅助损失(auxiliary loss),即将t+1时刻的行为作为标签来训练t时刻的兴趣h。除了正标签,作者也加入了与之相对的负标签,即随机抽取一个未进行操作的物品(这里的行为其实就是进行操作的物品)。辅助损失的形式如下:
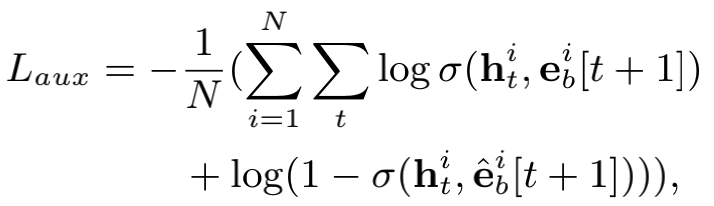
其中,
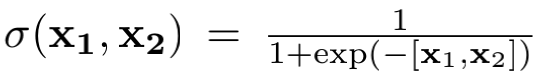
所以辅助损失本质上就是一种log loss,正样本对应标签1,负样本对应标签0,t时刻的隐藏层和t+1时刻的正负样本(即某个物品)的特征(即embedding)进行内积后作为特征来训练一个逻辑回归。当然这里没有逻辑回归的显式的权重,而是隐藏在GRU的训练和embedding的训练中,最小化辅助损失其实就是希望各个中间兴趣能够尽可能好地和下一个行为匹配上(这里转化为预测出下一个行为的发生)。辅助损失最终会乘以一个系数并加入总体的loss中。
下面我们来看一下兴趣抽取层的网络图:
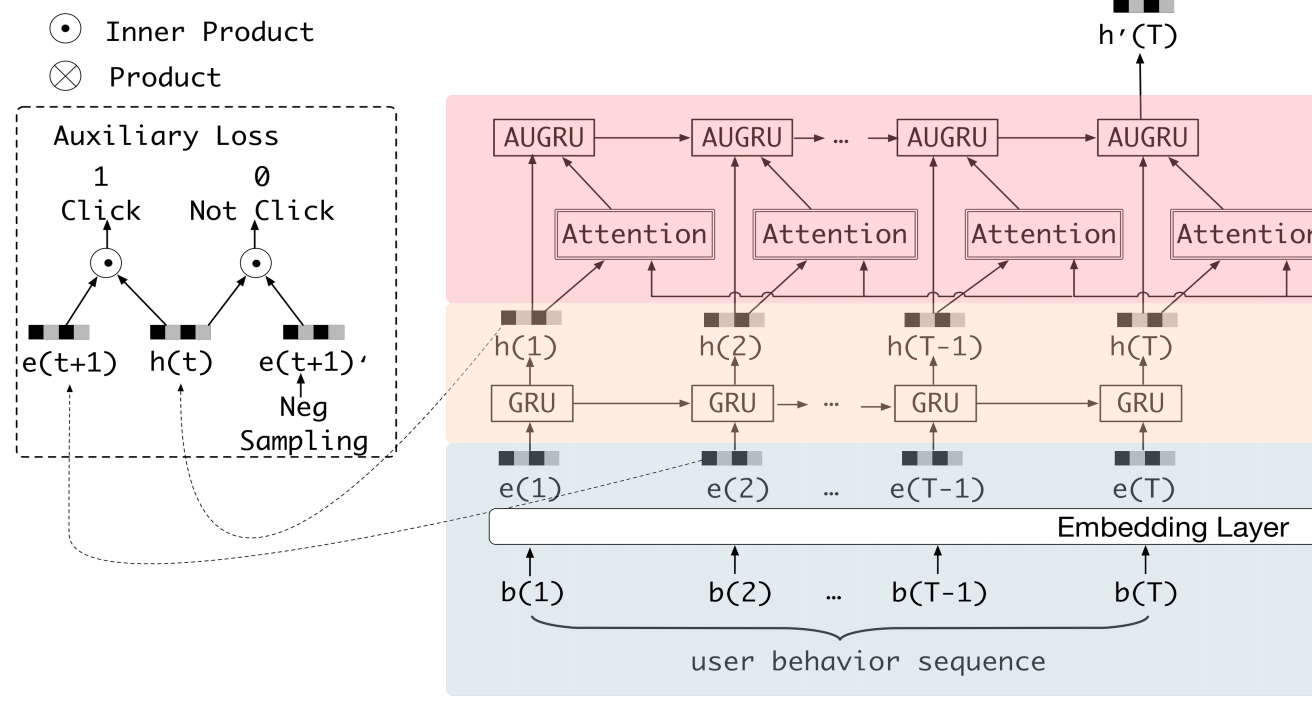
左边部分就是上面说的辅助损失,h(t)分别和正负样本做内积,并对应不同的标签。右边指明了正负样本出现的时刻是在当前隐藏层的下一时刻,即t+1和t时刻的关系。
最后提出两个个人的疑问:
- 为什么用隐藏层向量和正负样本做内积而不是拼接?
- 随机抽取负样本是否真的合适?(其实也是一个Positive Unlabelled learning的问题)
兴趣演变层
未完待续…