ESMM
ESMM[1]在多任务学习中比较特殊,因为其优化的两个目标 —— CTR和CVR,是有着严格的先后顺序的(转化行为必然发生在点击之后)。也正因如此,ESMM的通用性不强,但由于其瞄准的两个目标在推荐系统中是最重要的,因此这个算法的影响还是很大的。
ESMM主要想解决的两个问题分别是样本选择偏差(SSB,sample selection bias)以及数据稀疏(DS,data sparsity)。SSB其实就是在训练CVR模型时由于只对点击样本进行训练而产生的训练和线上样本的分布偏差。用户完整的行为链路是 曝光 -> 点击 -> 转化 ,离线训练的样本抽取的是点击样本,而线上预测时面对的则是曝光样本,那这中间肯定会有一个gap。DS则比较好理解,就是点击样本比较少,转化行为更加稀疏。
这两个问题我个人觉得第二个问题对于大厂来说应该还好,即便是点击样本那也是非常多的;第一个问题则确实是一个“痛点”。作者给出的方法是对CTR和CTCVR(而不是CVR)进行联合建模,CVR通过CTCVR/CTR间接得到。这样做的好处是可以利用所有曝光样本对两个目标进行训练,来解决SSB的问题;同时通过共享embedding层来解决DS问题。整个模型的结构类似于双塔,CVR和CTR通过相乘连接得到CTCVR。
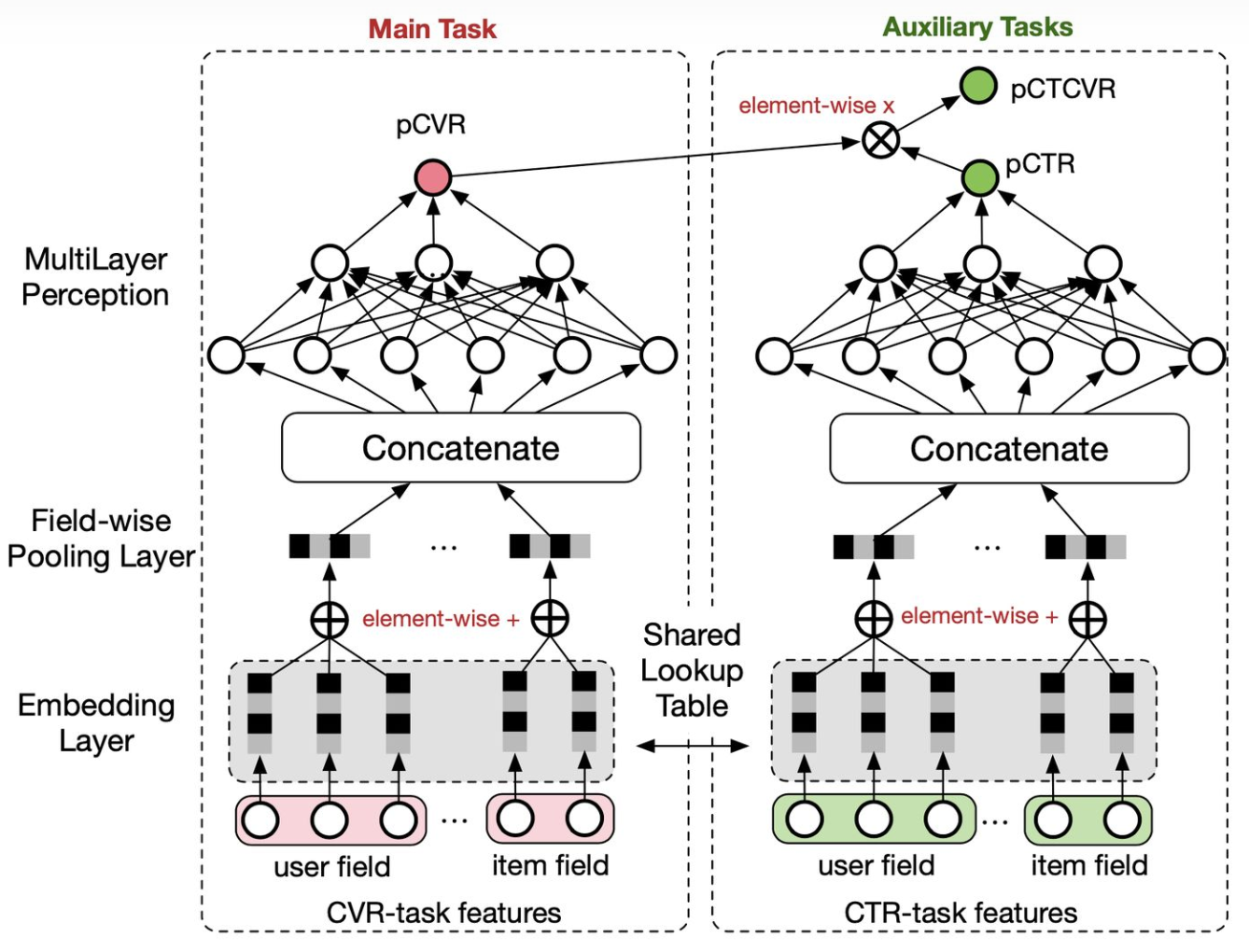
这个方法主要还是为了解决CVR预估上的问题,对于CTR任务来说效果可能一般,两个任务的效果容易出现跷跷板现象(即此消彼长)。
MMoE
MMoE[2]由底层共享(Shared-Bottom)演变而来。底层共享模型结构如下图(a)所示,其实就是多任务之间共享底层网络:
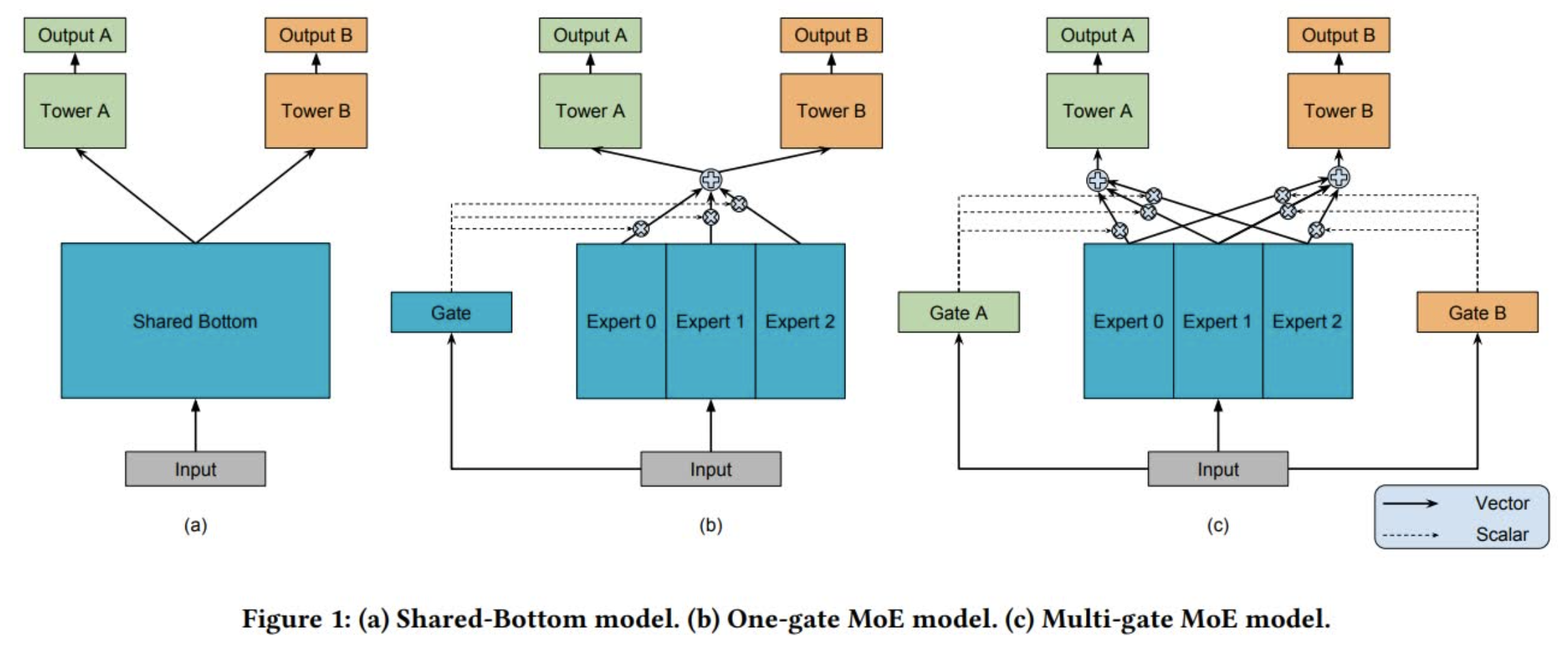
MoE(Mixture-of-Experts)基于底层共享进行了改进,将共享网络拆分成多个并行的子网络(即专家网络),并通过Gate进行各个专家网络的权重调节。这里对于各个任务,底层的网络仍然是一样的,不同任务都会对Gate和专家网络产生影响,因此可以理解为是多个底层网络的集成,集成权重由网络输入(即样本)自适应调节。当各个任务训练样本重合度比较小时,Gate或许也可以理解为一种和任务相关的对底层网络的集成控制,但是当重合度比较高时,这个区别或许就不明显了。此外,采用这种结构的好处是可以通过给Gate引入稀疏性而降低训练和测试时的计算量,带来性能提升。
MMoE(Multi-gate Mixture-of-Experts)在MoE的基础上引入多个Gate,每个任务都有一个独立的Gate,相当于每个任务都可以训练出一个和自身任务更匹配的专家网络加权网络。当各个任务之间的关联度比较小的时候,MMoE通过引入更多参数(即多个Gate)可以学习到对于不同任务来说更好的专家网络集成方式,通常也会比MoE取得更好的效果。此外,由于单个Gate的参数量比较少,因此即便是引入多个Gate,总体的参数量和MoE还是接近的,性能上的收益还是有的。
这篇[3]发表在RecSys2019上的文章描绘了MMoE是如何在Youtube视频推荐场景上应用的。这里的场景设定简单来说就是给用户推荐下一个他/她可能感兴趣并且愿意观看的视频,候选集是粗排后的几百个视频,这里要做的是进行进一步地精排。目标有两种,一种是参与目标(engagement objective),例如点击和观看;另一种是满意度目标(satisfaction objective),例如点赞和屏蔽。针对不同目标就可以采用MMoE构建不的Gate网络进行控制,整个网络架构如下图所示:
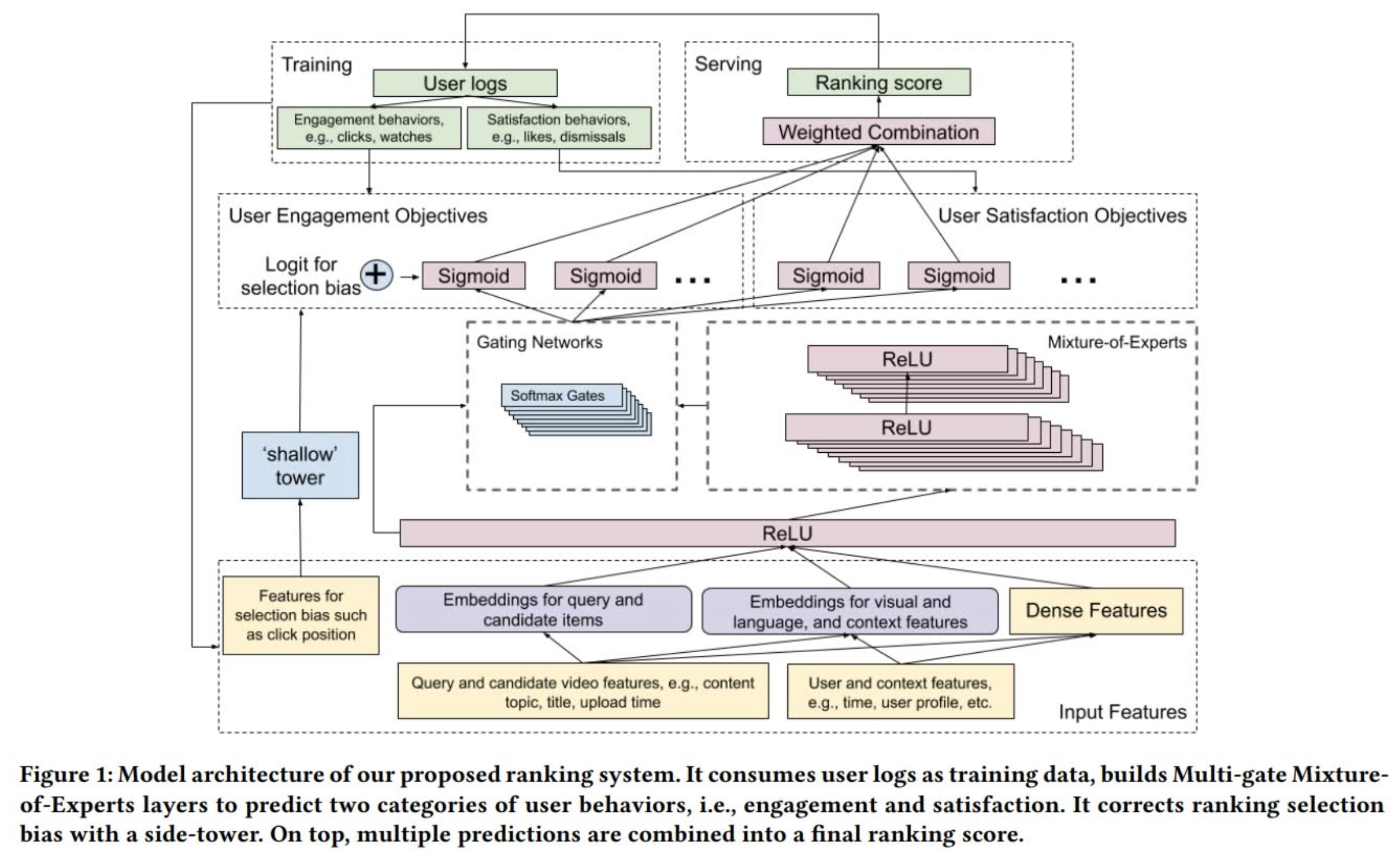
这里有一个细节比较有意思,就是在MoE层之前,输入层之后还有一层全连接层,它的作用主要是用来减少计算量。因为输入层的维度往往非常大,如果直接接MoE,那么有n个任务,参数就翻n倍,但是一旦接入一层全连接层(即shared bottom layer),那么参数会少很多。
此外这篇文章还针对推荐系统中的选择偏差问题提供了一个shallow tower(即上图左侧)来解决。选择偏差可以理解为一种系统偏差,例如位置偏差就是其中的一种。位置偏差是指在推荐过程中,推荐标的的位置往往会对用户行为(例如点击)产生巨大的影响,例如这里用户点击某个靠前的推荐视频可能并不是说这个视频是所有候选集中用户最感兴趣的,只是因为它比较靠前。如果不考虑这种偏差,推荐系统在不断训练迭代的过程中就会产生一个反馈循环效用(feedback loop effect),导致整个系统不断往某一个方向偏,有点类似于信息茧房。作者的解法是把这些和位置偏差相关的特征,例如视频位置和设备类型挑出来输入给一个浅层网络,并将网络的输出logits叠加到主模型的输出上。在预测时只把预测位置特征当做缺失值即可。这里还有一个小技巧就是在训练时随机丢弃10%的位置特征,以防止模型过于依赖位置特征。
SNR
SNR[4]全称是子网络路由(Sub-Network Routing),顾名思义就是提供一种对于每个任务来说更灵活的子网络联通方式。它和MMoE一样都是从Shared Bottom结构演变而来,相比于MMoE中各自独立的多个专家网络,SNR提供了一种更灵活的子网络切分和联通的方式(本质上也就是参数共享方式):
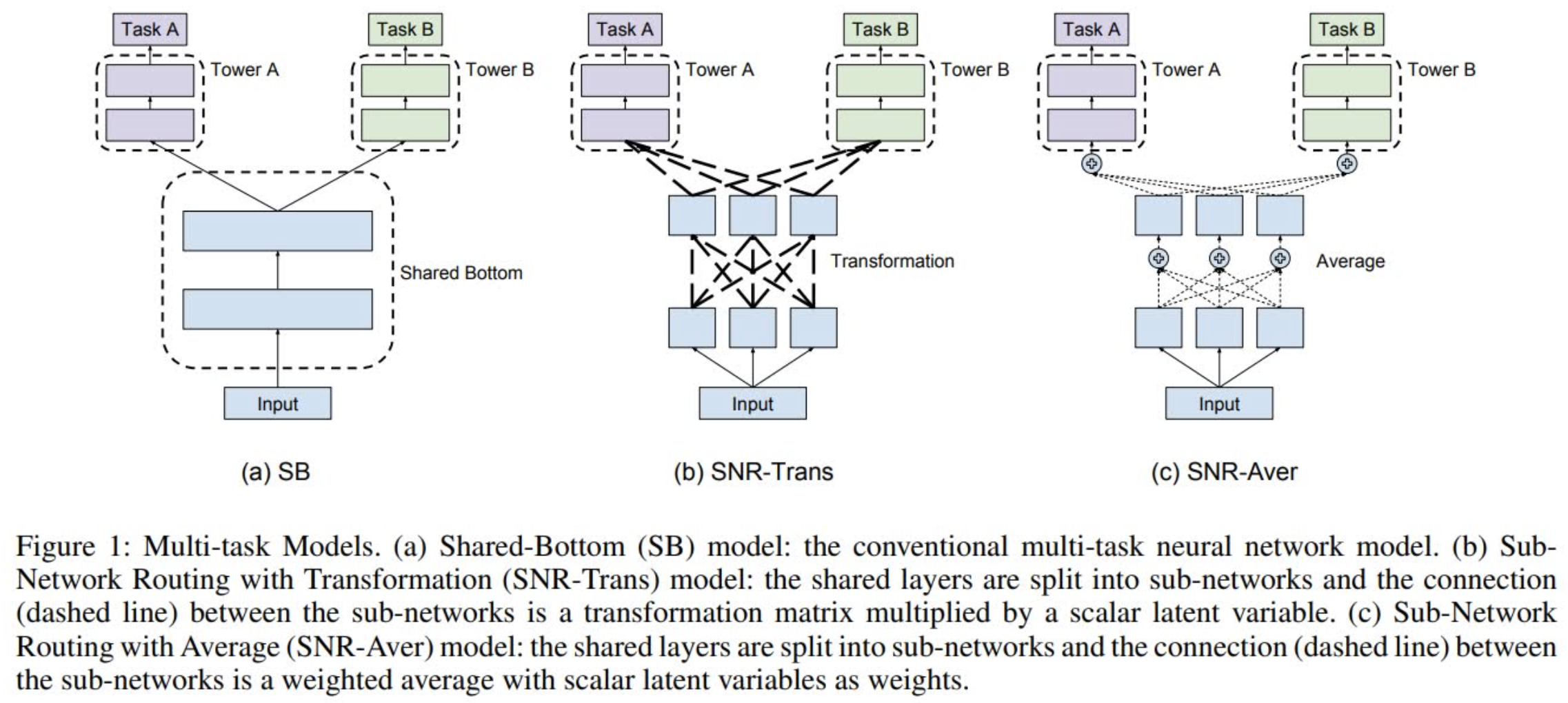
正如上图所示,SNR分成SNR-Trans和SNR-Aver两种。对于SNR-Trans,上下两层的子网络通过线性变换连接,而SNR-Aver则是直接加权平均。两个子网络之间是否联通由编码变量(coding variable)z决定,z=1表示连通,z=0则表示不连通。假设有两层相邻网络,其中 $\textbf{u_1},\textbf{u_2},\textbf{u_3}$ 分别表示低一层子网络的输出,而 $\textbf{v_1},\textbf{v_2}$ 则表示高一层子网络的输入,那么SNR-Trans可以被表示为:
![]()
其中 $W_{ij}$ 是从第 $j$ 个低层子网络向第 $i$ 个高层子网络的变换矩阵。而SNR-Aver则是:
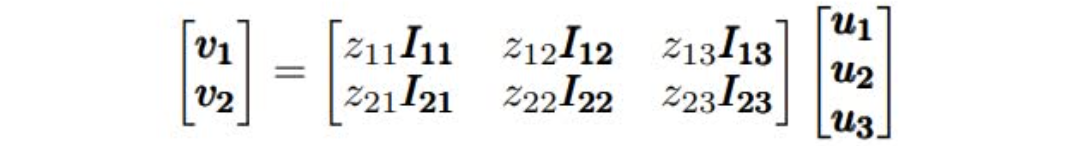
其中 $I_{ij}$ 就是单位矩阵。假设我们有两个相同参数个数的SNR-Trans和SNR-Aver模型,那么SNR-Trans模型就会在层连接上有更多参数,而SNR-Aver模型则是在子网络内有更多参数。也正因为如此,SNR-Trans网络更容易进行参数裁剪,因为只要某两个子网络不连接,就没必要有对应的变换矩阵;但是对于SNR-Aver网络来说,则必须某个子网络和所有其他子网络都不连接,才能被裁剪掉。
SNR模型结构的好处在于可以通过编码变量灵活地控制两个任务之间的参数共享程度,相关性高就多共享,相关性低就少共享。其问题则在于高度灵活性带来的调参难度(包括网络层数、子网络大小和个数以及编码变量的设置)。用NAS的方式去搜索网络结构,在推荐场景下个人感觉不是非常靠谱,计算消耗比较高。
Reference
[1] Ma X , Zhao L , Huang G , et al. Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate[J]. The 41st International ACM SIGIR Conference, 2018.
[2] Ma J , Zhe Z , Yi X , et al. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts. ACM, 2018.
[3] Zhao Z , Chi E , Hong L , et al. Recommending what video to watch next: a multitask ranking system[C]// the 13th ACM Conference. ACM, 2019.
[4] Ma J , Zhao Z , Chen J , et al. SNR: Sub-Network Routing for Flexible Parameter Sharing in Multi-task Learning[C]// AAAI 2019. 2019.