什么是延迟反馈问题
延迟反馈问题是指在转化预估场景下,由于转化行为相比点击行为存在一定滞后而造成的标签错误问题。以电商场景为例,用户在点击某个商品的商详页后往往需要一段时间来做出购买决定,可能是几分钟、几小时甚至是几天。在用户最终下单之前,没有人能知道这次点击会不会产生转化。
不过好在大部分人是不会花这么长时间考虑的。事实上,90%以上的转化都在点击后的一天内完成。如果把时间拉长到14天或者一个月,那基本上就没有多少“漏网之鱼”了。然而即使是14天,也是一个相对较长的时间,如果真的需要延迟这么多天才更新模型,黄花菜都凉了。由此我们可以看出延迟反馈造成的一个重要矛盾,即模型的时效性和标签的准确性之间的矛盾。
个人理解,所有用于解决延迟反馈问题的算法本质上都是在模型时效性的约束下优化模型的准确性,本文要介绍的ES-DFM[1]也不例外。下面就来看看ES-DFM是怎么做的吧。
场景设置
在看ES-DFM的具体算法之前,我们先来看看作者目标的应用场景是什么,因为目标场景往往决定了算法设计的内在逻辑。以本文为例,其目标场景是流式数据下的CVR建模,这就意味着对模型的时效性有着很高的要求。作者需要做的就是在频繁更新模型的情况下尽可能地保证模型的准确性。频繁更新模型带来的结果就是必然会有很多转化在一开始被误标为负标签,即false negative。那么问题就转化为如何在有较多false negative样本的情况下得到真实转化分布的无偏估计。
解决办法
先不考虑false negative样本的存在,即CVR模型的训练样本 $(x,y)$ 是依据其真实数据分布 $p(x,y)$ 采样得到,那么我们的目标就是最小化以下的Loss:
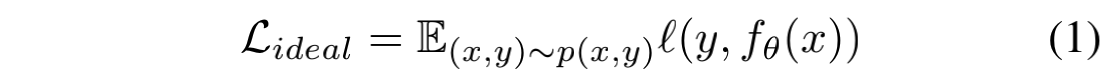
其中 $f$ 是CVR模型方程,$\theta$ 是模型参数。$l$ 是损失函数,例如交叉熵。
然而,由于延迟反馈的存在,我们事实上获取的样本只能是与真实分布有一定偏差的 $q(x,y)$ 。假设这两个分布比较接近,那么我们就可以利用重要性采样(Importance Sampling)方法,通过样本分布来估计真实分布。
重要性采样
重要性采样是蒙特卡洛方法中的一个重要策略。该方法不改变统计量,只改变概率分布,可以用来降低方差[2]。不过在这里,它更像是一个用于无偏估计的工具。看看下面的公式就明白了:
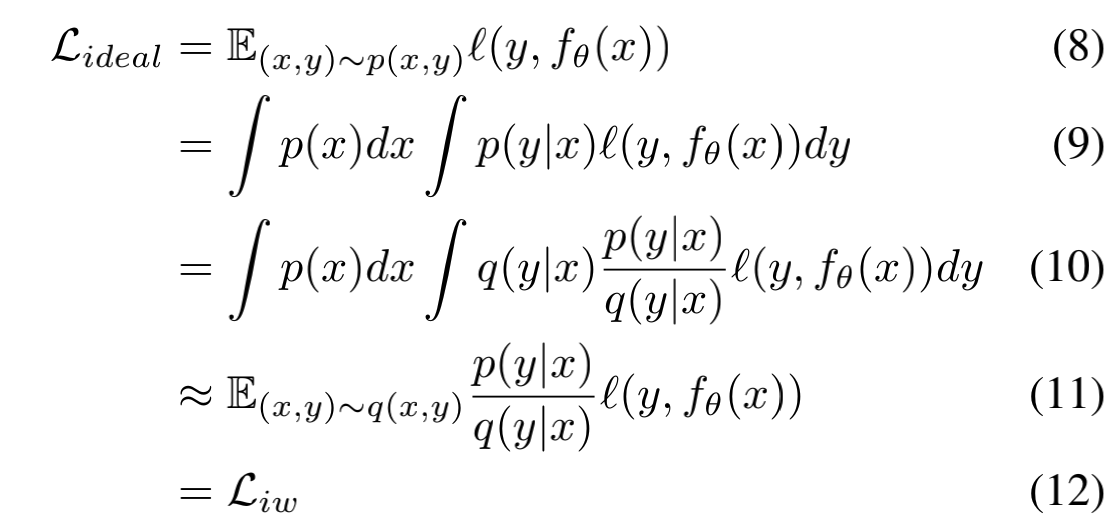
这里最重要的是(10)到(11)的这一步近似,直接就把样本分布从 $p(x,y)$ 转变到了 $q(x,y)$ ,不过这也要求 $p(x,y)$ 和 $q(x,y)$ 两个分布比较接近。这点能不能成立就要看具体应用场景了,我们这里先假设它成立。那么接下来只要能得到importance —— $\frac{p(y|x)}{q(y|x)}$ ,我们也就得到了理想状态下的损失L。
那么如何得到“importance”呢?我们知道,在延迟反馈场景中,有一种样本的标签是绝对真实的,那就是已经转化的样本。为了区分“已经转化”和“还未转化”,我们需要引入3个重要的时刻:即点击时刻 $c$ ,转化时刻 $h$ 以及当前时刻 $e$ 。很显然,对于 $y=1$ 的样本,必然是 $e > h$,而对于那些false negative样本,则是 $e < h$。下面这张图可以帮我们更好地理解:
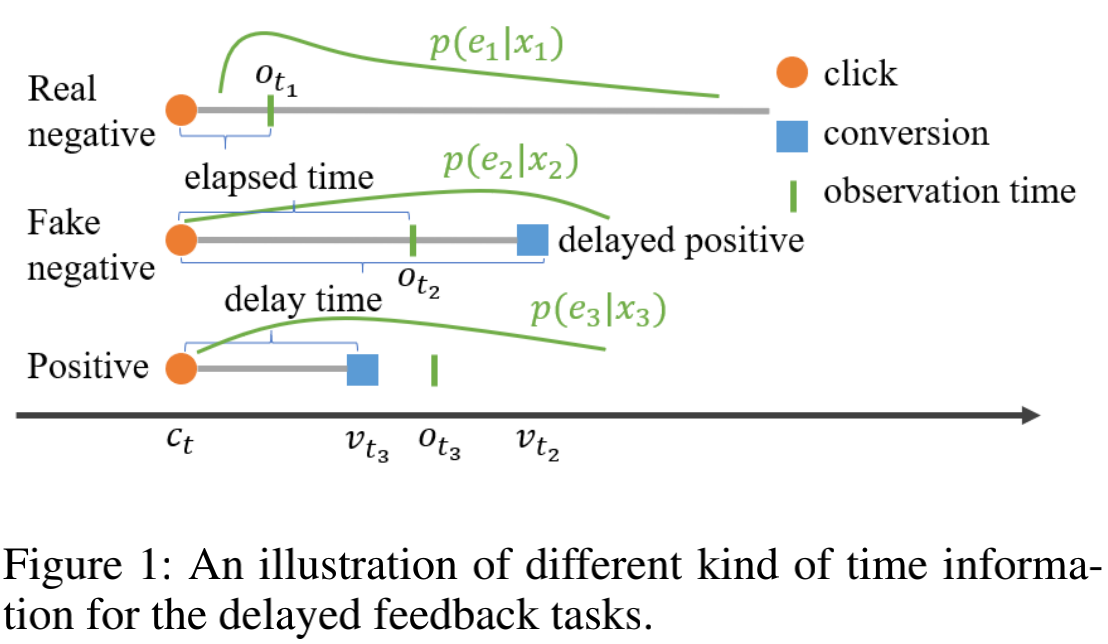
下面就是借助上面的概念对 $p(y|x)$ 和 $q(y|x)$ 的形式(或者说关系)进行推导了。由于在这里,y只有两个取值 0 和 1 ,因此无论是 $p(y|x)$ 还是 $q(y|x)$ ,我们都可以拆解为y=0时的条件概率和y=1时的条件概率。对于 $q(y|x)$ ,我们尝试用 $q(y|x)$ 来进行表征,即:
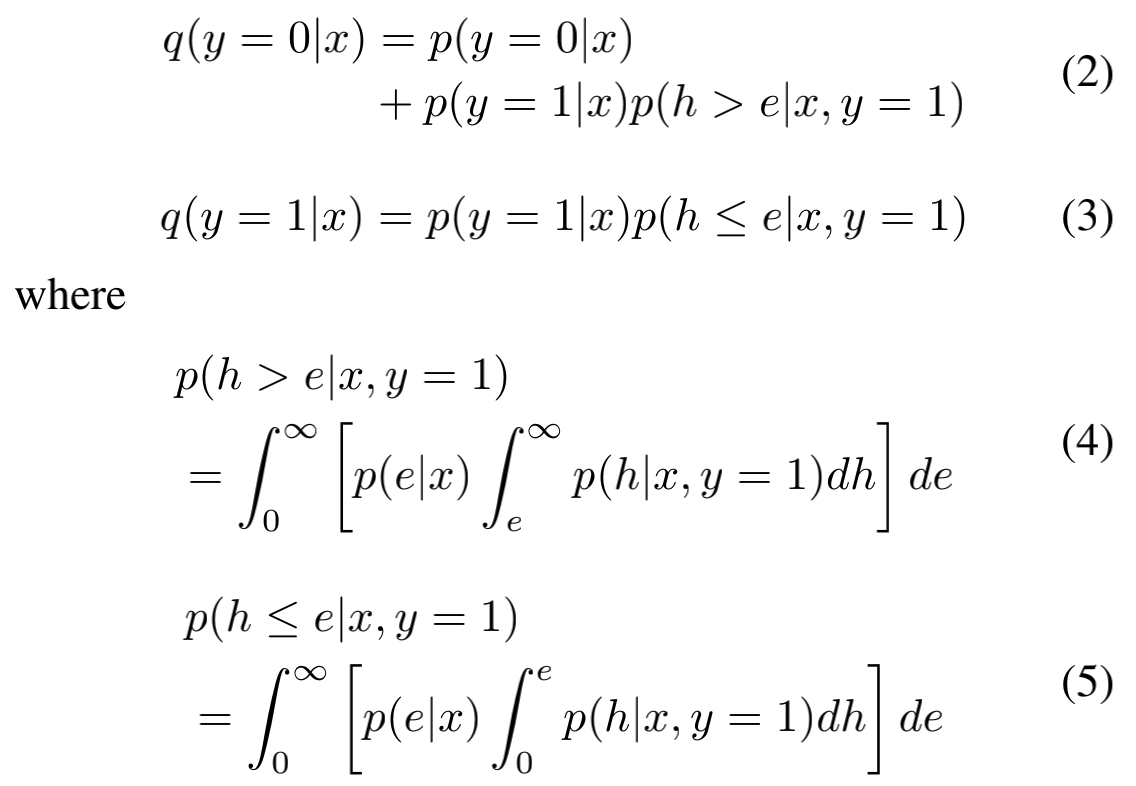
第一个式子实际上就是说:观测到的negative = true negative + false negative。false negative的概率就是 真实正标签的概率 * 当前时刻早于最后转化时刻并且最后确实会转化的概率(也就是 $ p(h > e|x,y=1) $ )。类似的,观测到的positive其实只是当前时刻晚于转化时刻的那一部分。考虑到正样本数量比较少,因此我们不能简单地把false negative给抛弃,而是需要在其转化完成后以正样本的形式重新加入到下一次的训练中。由于总体样本数会上升 $ p(y=1)p(h > e|x,y=1) $ 比例,因此也就需要除以 $ 1 + p(y=1)p(h > e|x,y=1) $ 来进行归一化:
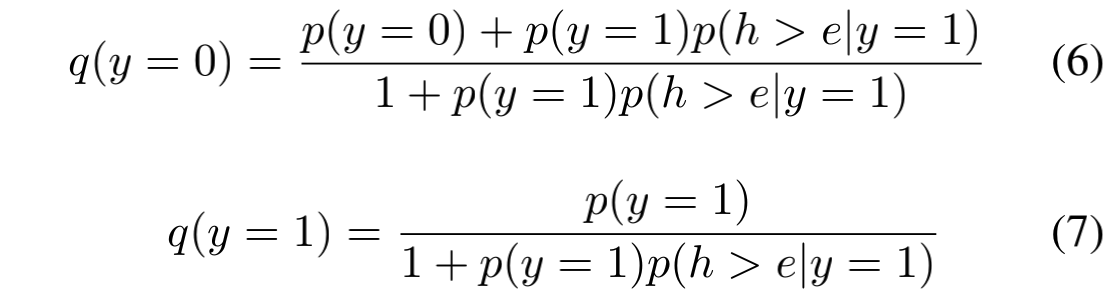
有了上述关系我们就可以进一步计算得到importance:
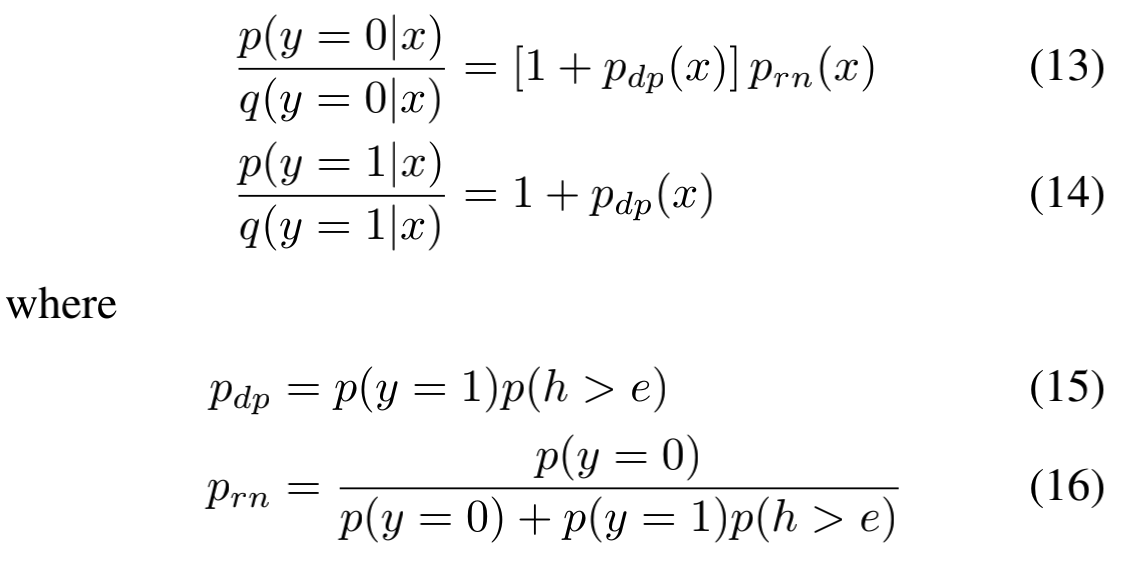
其中 $p_{dp}$ 是延迟正样本(delayed positive)的概率,即表示某个正样本是重复的正样本的概率(也就是转化后补充进来的);而 $p_{rn}$ 则是真实负样本(real negative)的概率,表示观测到的负样本“永远”不会转化的概率。由此我们可以得到最终的损失函数:
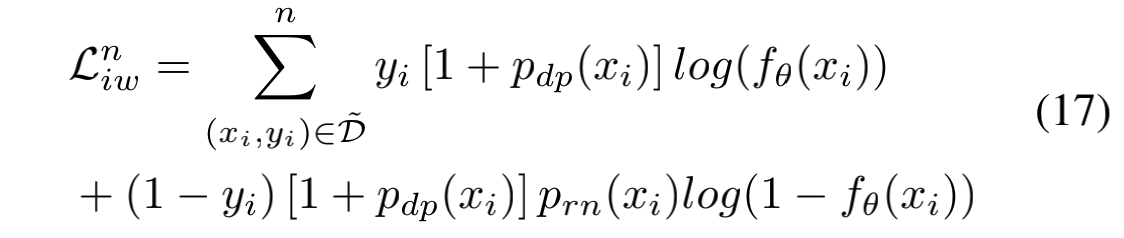
那接下来问题就转变为如何得到 $p_{dp}$ 和 $p_{rn}$ 。作者采用的方式是训练两个二分类模型,分别预测某个样本是延迟正样本的概率以及真实负样本的概率。由于预测值和真实的概率间存在gap,因此作者所期望的真实转化分布的无偏估计并不能够得到,终究是存在偏差的。此外,为了减小偏差,采样时刻 e 必须尽可能大,这也与作者设定的流式数据场景存在一定矛盾,相当于说还是需要进行妥协。
总的来说,本文解决问题的思路还是值得借鉴的。不过具体到落地的话似乎更适合实时性要求没那么高的场景,例如天级更新的模型。另外,由于要训练三个模型,对资源、稳定性和可维护性都提出了比较高的要求,感觉上成本可能有点高。不过由于总体流程不算复杂,个人觉得有条件的话还是可以试试看的。
Reference
[1] Yang J Q , Li X , Han S , et al. Capturing Delayed Feedback in Conversion Rate Prediction via Elapsed-Time Sampling[J]. 2020.
[2] 康崇禄.蒙特卡洛方法理论和应用.北京:科学出版社,2014:151