近些年来,NLP领域发展迅速,自BERT问世以来,基于Transformer架构的模型层出不穷,不断刷新NLP各个细分领域的榜单。作为一个NLP领域的门外汉,倒是也对Bert、ERNIE、GPT这些高大上的模型心生仰慕。不过路要一步一步走,这第一步便是Transformer。
第一步前的第零步
作为一个程序员,计数怎么能从1开始呢,那必须是0!在研究Transformer的原理之前,我们先得搞明白几个概念:encoder-decoder、attention以及self-attention。
Encoder-decoder
Encoder-decoder是之前机器翻译任务中最常用的架构,即将整个翻译过程拆分为encoder和decoder两部分。其中encoder将输入序列(其中每一个元素的表示为 $(x_1,…,x_n)$ )转换成一个向量 $\mathrm{z} = (z_1,…,z_n)$,之后decoder再以此向量为输入生成输出序列 $(y_1,…,y_n)$ (每个时刻生成其中的一个元素)。在每一步模型都是自回归的(auto-regressive),即在生成下一个结果时将之前已经生成的元素也作为额外的输入考虑进来。
Attention和Self-Attention
Attention就是大名鼎鼎的注意力机制。注意力机制和我们平时接受处理大量信息时的做法很像,由于没有办法吸收所有的信息,因此会挑选我们觉得“有用的”内容放在心里。就好比在历史期末考试之前,你可能会自己先划一下重点,然后再着重背诵这些“重点”知识。那么这里就有三个比较重要的地方:
- 如何判断什么是重点?在Attention中会引入所谓的查询向量(Query Vector),作为衡量“重点”的标尺。如果一个输入应该被“注意”,那么它和查询向量之间的相关性就应该很高。
- 如何量化重点的重要性?这其实就是上面说的计算输入向量和查询向量之间相关性的一个具体方法。一般来说由点积模型、缩放点积模型和双线性模型等。
- 对重点知识进行记忆加强。前面的步骤虽然重要,但是都是为最后一步做准备,因为我们的最终目的是“记住重点知识”。在Attention里,这个过程被表示成一个加权求和的过程,权值是上面提到的相关性(经过softmax归一化),而各个元素一般就是输入向量(也就是例子中的课本)。
这时候有点小机灵鬼可能会开始发散思维了:我为什么要按照权重记住所有词?我能不能就记住几个最重要的?我能不能在考唐朝历史的时候就只背唐朝的,在考宋朝历史时就只关心宋朝的重点呢?当然可以,这其实就对应于Hard Attention和Local Attention,而我们一开始说的是Soft Attention。不过,上面的例子只是为了更直观,可能不那么准确,有兴趣的小伙伴可以查阅更多的相关资料来学习,我们这里就不赘述了。
现在我们已经对Attention有了一个大概的理解,那Self-Attention又是什么呢?Self-Attention即自注意力,其输入向量和查询向量都是原始输入向量的线性变换,即自己跟自己算Attention。自注意力模型通常采用QKV对(Query-Key-Value对)模式,其计算过程如下图所示(摘自《神经网络与深度学习》):
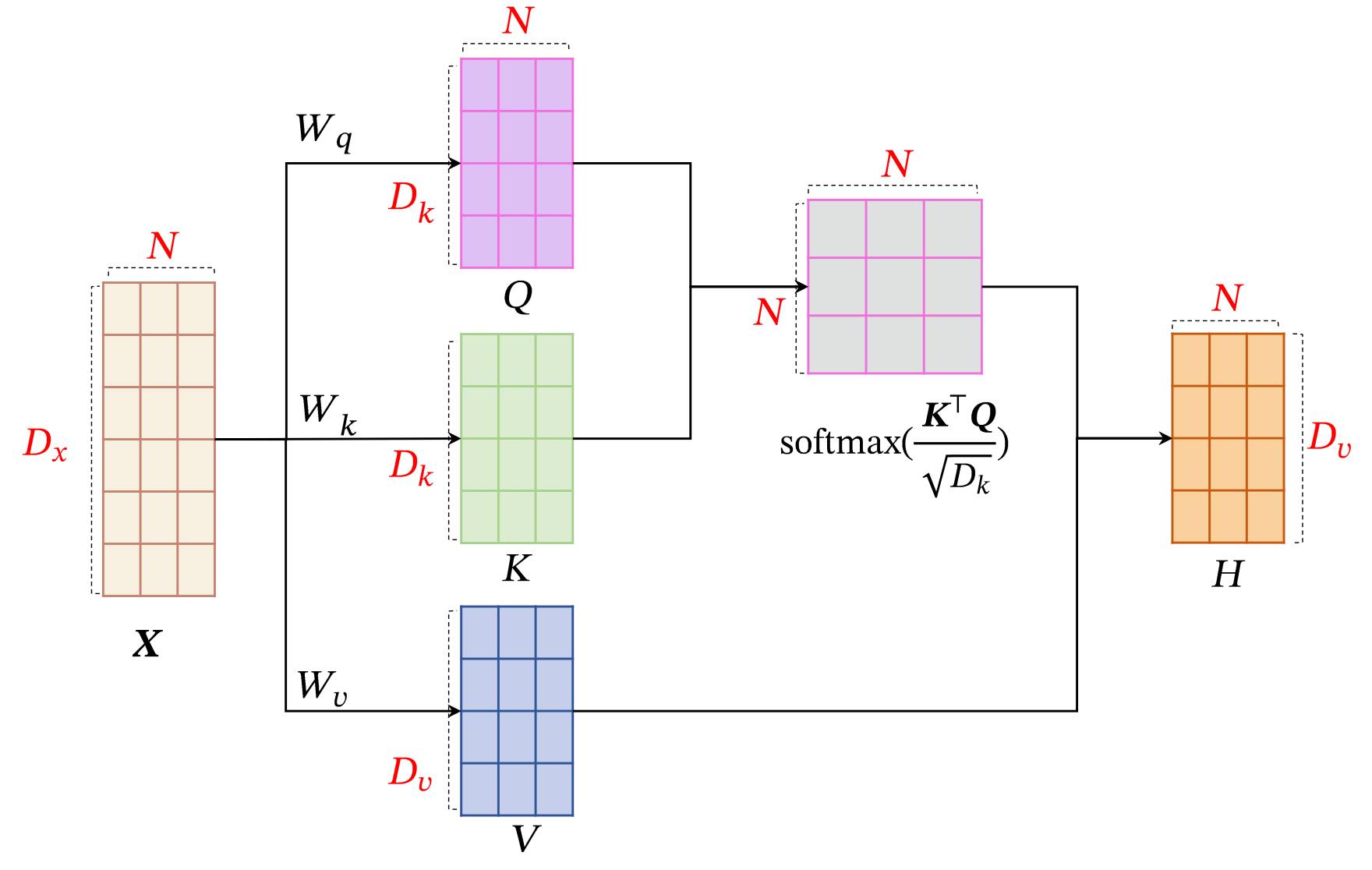
假设输入序列是Dx*N的矩阵(Dx表示输入向量维度,N表示样本数),那么分别经过Wq、Wk和Wv三个线性变换后,可以得到Q、K、V矩阵(注意这里Q和K的维度要相同,但是并不一定要和V相同)。Q和K可以进一步通过缩放点积来进行打分,并经过Softmax归一化得到V矩阵的权重,从而计算得到最终的输出向量序列H:
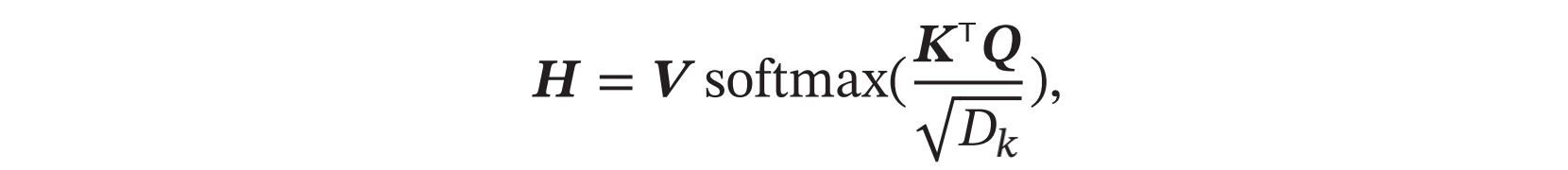
Transformer结构
在了解了Encoder-Decoder以及Attention之后,我们来看一下Transformer的结构:
![]()
Encoder部分
可以看到,Transformer也是分为Encoder和Decoder两部分,其中Encoder是先将输入经过embedding,得到embedding向量,之后加入位置编码信息(Positional Encoding)传入N个相同的层(layer)。每个层又可以分为两个子层,其中第一个是多头注意力(Multi-Head Attention),而第二个则是一个简单的逐位置的前馈神经网络(Position-wise Feed-forward network)。每层之后的Add&Norm指的是一个残差连接+LN(Layer Normalization)。因此每一层的输出都可以表示为:LayerNorm(x + Sublayer(x)),其中Sublayer(x)就是上面说的多头注意力或者前馈网络的结果。
LN是BN的一个改进或者说变种。BN是对不同样本的同一特征(通道)做标准化,而LN则是对同一样本下的不同特征(通道)做标准化(这里的“特征”是指某个隐藏层的节点数量)。在RNN中通常使用LN而不是BN,这是因为RNN是一种动态网络,其展开后的隐层数量会随着时间片数量的增加而增加,因此一个batch内的样本很可能拥有不同的长度,由此得到的统计量也是不充分的。更多LN相关知识可参考https://zhuanlan.zhihu.com/p/54530247。
残差连接就是通过将输入直接累加到输出上,从而使得中间的神经网络部分拟合的是输出和输入之间的残差。假设输入是x,中间的非线性变换方程为F,那么输出就是y = F(x)+x。残差连接可以有效地改善反向传播中存在的梯度弥散问题,并且通过打破网络的对称性,来提升网络表征能力。关于残差连接的更多相关知识可以参考https://zhuanlan.zhihu.com/p/80226180。
这时有人可能会问了:多头注意力是什么?逐位置的前馈神经网络又是什么?位置编码是干什么用的?
多头注意力
在介绍自注意力时我们提到可以通过三个不同的线性变换,得到Q、K、V矩阵。假设我们将这三个线性变换看做是一组,那么我们其实可以多训练几组来增强自注意力模型的学习能力(多组不同的线性变换即所谓的多头)。多头注意力的结构如下所示:
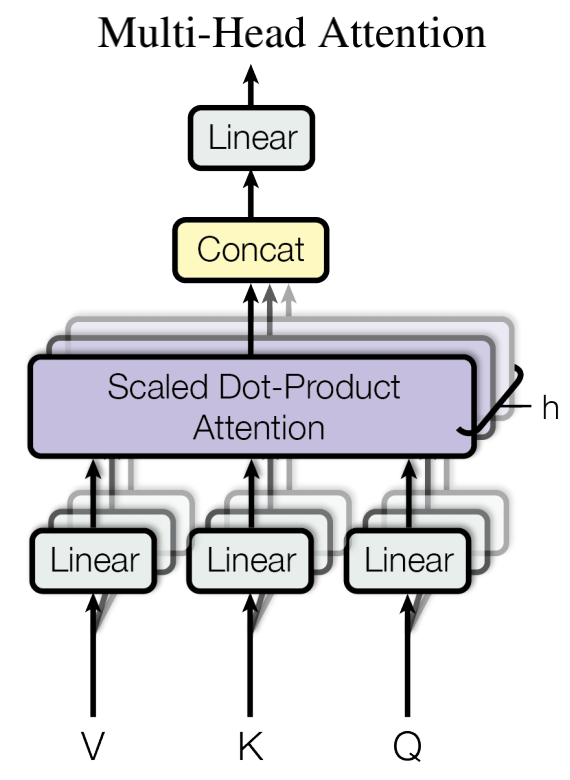
假设我们一共应用h组线性变换,那就可以得到h个结果矩阵,将它们拼接起来再做一次线性变换,即可得到最后的结果:
 其中 $W^{Q}_{i} \in \mathbb{R}^{d_{model}\times{d_k}}$ ,也就是我们前文提到的Wq,Wk和Wv也是类似,而 $W^{O} \in \mathbb{R}^{hd_v \times{d_{model}}} $ 。为了加快计算速度,可以并行计算每个head,并且减少每个head的维度。在论文中,作者设置h=8,并且$ d_k=dv=d_{model}/h=64 $ 。
其中 $W^{Q}_{i} \in \mathbb{R}^{d_{model}\times{d_k}}$ ,也就是我们前文提到的Wq,Wk和Wv也是类似,而 $W^{O} \in \mathbb{R}^{hd_v \times{d_{model}}} $ 。为了加快计算速度,可以并行计算每个head,并且减少每个head的维度。在论文中,作者设置h=8,并且$ d_k=dv=d_{model}/h=64 $ 。
逐位置的前馈神经网络(FFN)
FFN其实就是一个简单的二层网络,其中第一层的激活函数为ReLU。对于输入序列中每个位置上的向量x:
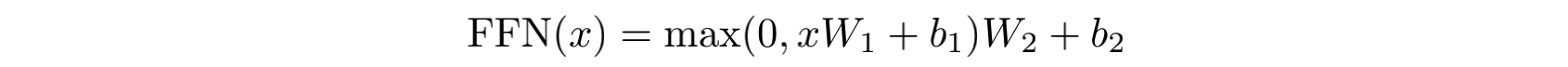
在同一层上(这里指的是Encoder或Decoder内的层),每个位置上的向量x所对应的参数W1、W2、b1、b2都是相同的,但是层与层之间的参数时不同的。FFN的作用应该就是提供更多的非线性和学习能力。
位置编码
由于Transformer的结构会丢失输入序列的顺序信息,因此这里采用位置编码的方式将序列中每个token的相对或绝对位置信息纳入整个训练过程。位置编码是加在所有encoder和decoder层的一开始,并且被加到输入和输出向量中(通过下图回顾一下transformer的架构)。
![]()
由于位置编码需要能和输入输出embedding做加法,因此它们的维度都是 $d_{model}$ 。位置编码的方式有很多种,这里作者选择不同频率下的正余弦方程:
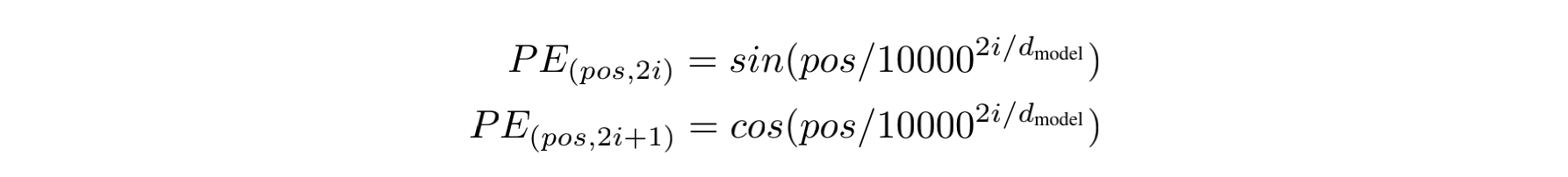
式子中的pos是位置,i是维度。不得不说,原论文这一段写的真的是垃圾,完全不知道在说什么,因为它既没有解释细节,也没有解释原因。首先是公式的一些细节:
问题1: 既然i表示维度,那么 $2i/d_{model}$ 的取值范围应该是[0, 2],由于波长等于 $2\pi*10000^{2i/d_{model}}$ ,那么取值范围不应该是 $2\pi$ ~ $10000^{2}\cdot2\pi$ ,为什么是 $2\pi$ ~ $10000\cdot2\pi$ 呢?
原因其实很简单,那就是i的取值范围根本不是0到 $d_{model}$ ,而是0到 $d_{model}/2$ 。这时你的脑袋里可能又会冒出第二个问题:
问题2:PE(pos, 2i)和PE(pos,2i + 1)到底代表啥?最后的编码到底是个什么形式?
其实PE是一个向量,PE(pos, 2i)和PE(pos,2i + 1)都是其中的元素。由于i的取值范围是0到 $d_{model}/2$ ,因此最终的编码向量长度也才能等于 $d_{model}$ 。例如第一个位置的位置编码为 $PE(1)=[sin(\frac{1}{10000^{0/d_{model}}}), cos(\frac{1}{10000^{0/d_{model}}}), sin(\frac{1}{10000^{2/d_{model}}}), cos(\frac{1}{10000^{2/d_{model}}}),…,sin(\frac{1}{10000}),cos(\frac{1}{10000})]$ 。
到这里我想你大概能看懂位置编码是个啥了,不过作者为什么要这么做呢?位置编码的作用是要在训练中注入每个token的位置信息,因此一个好的位置编码方式应该拥有以下几个特点:
- 不同位置的编码不同。
- 编码能够体现出token的绝对位置或相对位置。
- 编码函数最好是个有界函数,否则不同长度的序列带来的编码范围会差别很大。
- 不同维度的编码应该有差异性。
基于以上几点,作者采用三角函数形式的位置编码。关于位置编码更多的解读可以参考https://www.zhihu.com/question/347678607。
Encoder部分总结
简单总结一下Encoder部分,主要分为3个部分:
- 输入Embedding
- 位置编码
- 多层网络
其中第三部分又可以分为两部分(假设上一层的输入为 $H^{(l-1)}$ ):
- 多头注意力+残差&Norm: $Z^{(l)}=Norm(H^{(l-1)} + Multi-Head(H^{(l-1)}))$。
- FFN+残差&Norm:$H^{(l)}=Norm(Z^{(l)} + FFN(Z^{(l)})$。
Decoder部分
聊完了Encoder部分我们再来看看Decoder部分。相比于Encoder,Decoder内的第一个多头注意力多了一个前缀 —— Masked,这个Mask是指什么呢?
Masked Multi-Head Attention
我们知道多头注意力是一种自注意力机制,因此其Q、K、V的源头都是输入序列自身。在Decoder部分,输入是我们的“标签”,即最终想要预测的内容(例如英翻中里面的中文翻译结果),那么为了防止信息泄露,我们在预测第k个词的时候肯定不能事先知道第k个词乃至其后面的内容,而只能知道我们已经预测过的前k-1个词。因此在运用多头注意力时需要把第k个词之后的内容进行隐藏,即所谓的mask。作者的做法是将需要被mask的向量设置为负无穷,那么经过点积和softmax之后其结果趋近于0,对最终结果也几乎没有任何影响。
承接Encoder输出的多头注意力模型
Masked多头注意力的输出会接入另一个多头注意力模型,但不同于Encoder内的是,它不再是一个自注意力模型,因为其Q、K、V的来源不再相同。Q来自于Masked多头注意力的输出,K、V则是由Encoder的输出经过线性变换得到。它的作用就是让Encoder的编码结果通过Attention的方式传递给Decoder,其实跟原始的带Attention的Encoder-Decoder模型的结构是一样的。
再之后就是和Encoder中一样的FFN + Add&Norm。在N层Decoder层之后,结果会进行一个线性变换,并且通过Softmax转化成不同类别的概率值,这部分跟其他传统的神经网络模型都是一样的。
为什么要采用Self-Attention
从上面的分析我们可以看到,Transformer和传统基于RNN的带attention的Encoder-Decoder模型最大的区别其实就是采用位置编码+多头注意力(Self-Attention)+FFN的方式替代了原来的RNN或LSTM等序列模型。其中位置编码是为了注入位置信息(这个算是补偿没有位置信息的短板,算不上优势),FFN是为了进一步增加非线性和学习能力(我的理解是对Self-Attention学习能力的加强),最主要的改变还是多头注意力,或者说Self-Attention的结构。那么为什么要采用这种网络结构来替代RNN呢?
作者在论文中给出了这种结构的3个优势:
- 每一层的计算复杂度更小。
- 总体的计算并行度更大。
- 网络中长距离依赖间的路径长度更小。
其中第二个优势可以通过测量必须要依顺序执行的操作数来证明,而第三点的其中一个重要的影响因素是前向和后向信号在网络中必须要经过的路径长度,如果输入和输出序列任意位置间的上述路径长度越短则可以越容易地学习到长距离依赖。具体的对比结果如下图所示:

由于序列长度n一般小于表示向量的维度d,因此self-attention的每层计算复杂度通常小于RNN和CNN结构。上图中最后一行的restricted是指self-attention被限制到只考虑以输出位置对应输入位置为中心周围大小为r的邻域节点。这种做法会增大最大路径距离到O(n/r),不过每一层的计算复杂度会有所减少。
上述三个优势的前两个是从计算效率的提高上说的,而最后一个则是针对模型效果。每一层的计算复杂度更低,并行效率更高意味着可以堆更深的网络,也能更快地得到模型效果评估结果。不过在实际应用中,模型的大小也很重要,参数量过大会对模型的存储和inference的效率提出更高要求。Bert的base model参数量有110M,large model有330M,还是很惊人的,可见深度学习对算力的要求越来越高,大厂滚雪球式的技术优势将来可能越来越大。
Transformer代码分析
未完待续