再说两句
最近碰巧又在arXiv上看到两篇用知识蒸馏做联邦学习的文章,和之前介绍的思路还不太一样,因此这里另起一篇做一个简单的补充。没有直接放到上一篇文章也是因为我个人感觉这两个思路还不是很成熟(有点不靠谱),不过相对比较新颖,可以记录一下。这两篇文章分别是:
- Adaptive Distillation for Decentralized Learning from Heterogeneous Clients
- Distilled One-Shot Federated Learning
DLAD
第一篇文章提出了Decentralized Learning via Adaptive Distillation(DLAD),其中Decentralized指的是数据非中心化(联邦学习的范式),Adaptive则是指蒸馏过程可以动态调整。DLAD的核心在于引入无标签数据下的知识蒸馏。
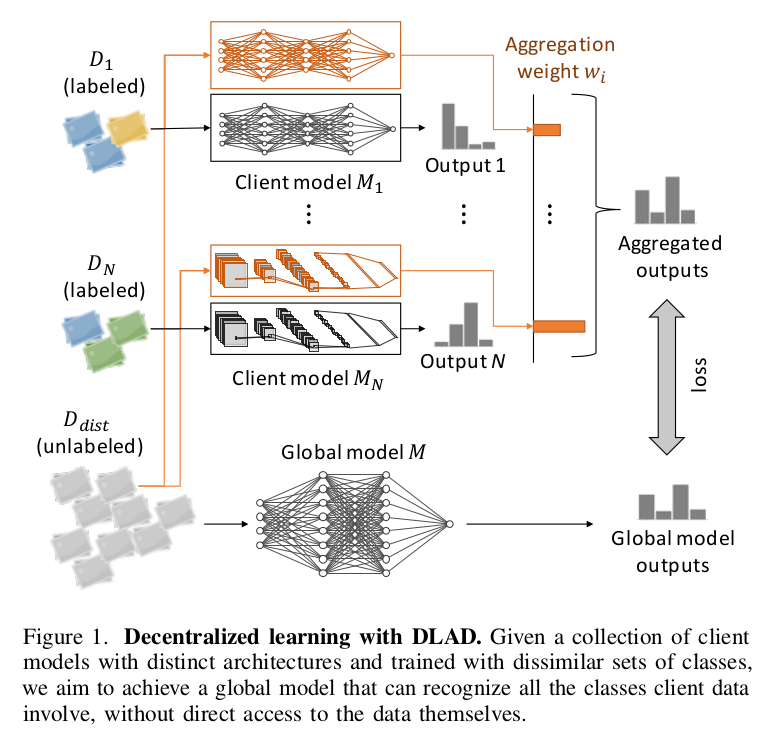
上图是DLAD的训练过程。DLAD会聚合每个client模型的输出来进行自适应的知识蒸馏。对于每个蒸馏样本,当client模型的私有数据中有和其相似的样本时,模型的结果被认为是confident的,并且通过更高的权重来emphasize。之后可以利用这些聚合的输出来训练全局模型。而confident的训练则可以通过另一个分类模型完成。和FedMD类似,DLAD对于每个client模型的类型也不要求一样。
个人感觉DLAD更像是用local数据来给全局数据打标签,适合于有大量无标签公共样本的场景。另外confident的判断有可能会泄露数据,如果进行模糊又可能影响效果。
Distilled One-Shot Federated Learning
这篇文章把数据蒸馏和one-shot learning结合到一起,可以说是提供了一种完全不同的联邦学习思路。这里作者通过数据蒸馏同时进行了数据压缩和隐私保护,而在之后将所有蒸馏数据进行聚合并训练全局模型。因为首先进行了数据蒸馏,所以传输的数据量比较小,并且只需要传输一次就能达到一个不错的效果。下图是其算法流程。

数据蒸馏的方式参考了文献[3]。为了在non-iid的数据集上取得不错的效果,作者还提出了soft reset和random masking对上述算法进行改进。
然而这种方法有一个问题,那就是安全性没有可靠保证。尽管作者专门花了一小段来说明其安全性,并且还是有些道理的,但是考虑到文献[3]指出:
In addition, these distilled images often look quite informative, encoding the discriminative features of each category (e.g., in Figure 3).
数据蒸馏的安全性到底如何还很难说。如果想用类似的方式来做联邦学习,那么安全性的证明可能是最重要的。
Reference
[1] Ma J , Yonetani R , Iqbal Z . Adaptive Distillation for Decentralized Learning from Heterogeneous Clients[J]. 2020.
[2] Yanlin Zhou, George Pu, Xiyao Ma, Xiaolin Li, Dapeng Wu. Distilled One-Shot Federated Learning.
[3] Wang T , Zhu J Y , Torralba A , et al. Dataset Distillation[J]. 2018.