前言
在上一篇文章中我们梳理了一下采用元学习方法进行个性化联邦学习的几种方式,本文中,我们将继续探寻如何将知识蒸馏应用于个性化联邦学习。在本文的一开始,我想先简单介绍一下知识蒸馏。
什么是知识蒸馏
知识蒸馏最早由Hinton等人提出,用于将复杂模型(集成模型)内的知识压缩到简单模型(单个模型)中[1]。做法就是将复杂模型得到的预测概率值作为soft target,辅助真实标签(hard target)一起训练。这样做的原因在于soft target拥有更高的熵,因此单个样本可获取的信息更多,所以小模型就不需要那么多样本进行训练,学习率也可以设置的比较高。
一般来说,在神经网络的训练中我们会在最后使用softmax来将每个类别对应的logit $z_i$ 转换为概率值 $q_i$ 。为了得到一个更小的损失,我们需要让正确标签对应的概率值尽可能大。因此在很多时候,正确类别对应的概率值可能很高(例如0.98),而其他类对应的概率值可能很小,这也就导致soft target和hard target的差别不大,但这显然和我们的期望背道而驰。因此论文中提出温度系数T,用来平滑各个类别对应概率值之间的差距:
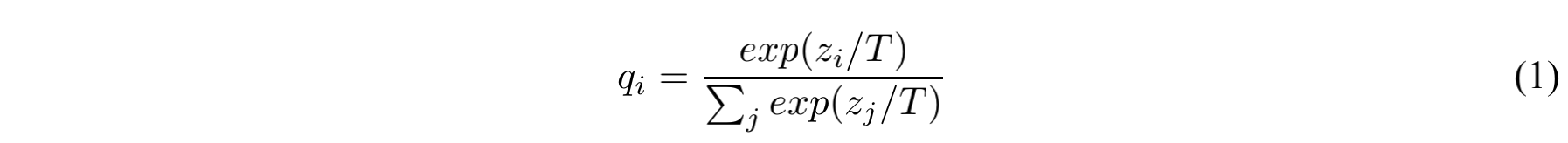
最终的loss可以看做是基于soft target和hard target进行训练的loss的加权和:
$$ L = \alpha*L_{soft} + (1 - \alpha)*L_{hard} $$
知识蒸馏与联邦学习
在知识蒸馏中,我们也会把复杂模型称为teacher model,把简单模型称为student model,因为蒸馏的过程就类似于学生向老师讨教的过程。那么在联邦学习中teacher model和student model又分别是什么呢?这里我们以下面两篇文章为例介绍一下两种不同的思路:
- Salvaging Federated Learning by Local Adaptation
- FedMD: Heterogenous Federated Learning via Model Distillation
Salvaging Federated Learning by Local Adaptation
这篇文章的思路是将横向联邦中的全局模型看做teacher model,而将每个参与方本地的模型看做student model。和传统横向联邦的架构一样,本地模型和全局模型的结构是相同的,不同的只是各自的参数。并且本地模型的初始参数被设置为全局模型。teacher model和student model之间的知识传递通过优化KL散度loss来进行,而hard target部分采用的是交叉熵损失。
这种方法更像是对于fine-tuning的一种改进。fine-tuning本身很容易造成过拟合(特别在样本量很少时),而知识蒸馏其实会让hard target变得更加soft,所以实际上也就缓解了过拟合的问题。
除了知识蒸馏的方式之外,作者还给出了fine-tuning和multi-task learning的两种个性化联邦学习方法,有兴趣的同学可以看一下论文。
FedMD
虽然都是进行个性化联邦学习,但这篇文章关注的侧重点跟以往的方法都不太一样。在以往的方法中,本地模型和全局模型的结构必须相同,所谓的个性化更多是指参数的不同。但事实上在很多场景下,这种同构限制会比较大。一方面是因为不同的数据和计算资源可能会使这种同构的要求存在一个性能上的瓶颈,另一方面各个参与方(尤其是企业场景)很可能希望能够决定本地模型的结构,而不是只能使用统一的结构。
以往的算法需要传递模型或梯度,因此肯定是无法支持这种本地黑箱模型的场景的。作者想到的解决办法是对传递的信息进行更高level的抽象,因为本质上联邦学习中各个参与方需要传递的是解决问题的能力,而不一定是所谓的模型或梯度。那么还有什么东西能表征这种能力呢?你可能已经想到了,那就是知识蒸馏里的知识。作者将传递的内容从模型本身转变为知识后,不仅解决了上面的那个问题,同时也在模型参数很多的情况下大大减少了通信量。
不过解决了通信的内容之后仍然存在两个问题。一个是知识哪里来,另一个是知识如何汇聚。第一个问题作者是通过使用外部数据集来完成的,即假设除了本地私有数据外还有一个公开数据集(这个对场景的限制会比较大);第二个问题作者直接采用了将知识(这里是class score)平均的做法。总体的算法流程如下:

从上面的流程也可以看出来,整体的结构还是比较简单和基础的,作者本人也将其称为FedMD v0,表示这是一个很初期的版本。不过我个人觉得还是很有意思的,因为将联邦学习的做法进行了高level的抽象,相当于是扩大了应用场景,提供了更多思路。作者也在这个视频里面说了,除了知识蒸馏也可以考虑其他获取知识的方式。
总结
目前将知识蒸馏运用在个性化联邦学习场景下的算法还不是很多,目前已有的方式有两种,一种是利用知识蒸馏来缓解微调带来的过拟合问题,另一种是利用知识蒸馏对训练过程中的知识进行提取并传递。在下一篇文章中,我将继续介绍除了元学习和知识蒸馏以外的其他进行个性化联邦学习的方法,并对个性化联邦学习做一个总结。
Reference
[1] Hinton G E, Vinyals O, Dean J, et al. Distilling the Knowledge in a Neural Network[J]. arXiv: Machine Learning, 2015.
[2] Yu T, Bagdasaryan E, Shmatikov V, et al. Salvaging Federated Learning by Local Adaptation[J]. arXiv: Learning, 2020.
[3] Li D, Wang J. FedMD: Heterogenous Federated Learning via Model Distillation.[J]. arXiv: Learning, 2019.