什么是个性化联邦学习
当初在刚学习联邦学习不久时,我的脑海中就有过一个疑问:
通过联邦学习训练出来的模型就一定比本地数据训练出来的模型效果更好吗?
似乎联邦学习只关心总体的情况,而忽略了个体,因为它的全局模型是基于所有数据进行训练的,并且优化的目标也是一个整体目标。然而我们都知道,在联邦学习的设定中,不同参与方的数据量和分布都是不同的,全局模型无法在把握整体的同时又照顾到这种差异。当某一方的数据和整体偏离比较大时,联邦学习的效果确实有可能不如本地训练的效果。这就带来一个问题:我为什么要进行联邦学习?对于某个参与方而言,他其实并不关心(或者说没那么关心)所有参与方总体的收益变化,而是更关心自己的收益,而这也就引入了所谓的个性化联邦学习。
个性化联邦学习和传统联邦学习的区别在于它并不要求所有参与方最终使用的模型必须是一样的,而是允许每个参与方根据自己的数据对模型进行微调,从而生成本方独特的个性化模型。在进行个性化微调之后,往往模型在本地测试集上的效果会更好。
这里需要注意的是,尽管个性化联邦学习和传统联邦学习的目标都是希望模型在本地数据集上的效果最好,但是由于个性化联邦学习并不要求最终模型相同,因此它们的训练目标还是有所区别的,并不是说个性化联邦学习就是简单的先用传统联邦学习的方法得到全局模型,然后再在此基础上进行微调就可以了。
注:当然谷歌最早做这个研究的时候就是用的这种比较Naive的方法,具体的我们会在之后的文章中进行介绍。
个性化联邦学习的方法有很多,我们将在本文着重介绍其中一个“流派”,即利用元学习的方法来进行个性化联邦学习。在此之前,先简单介绍一下什么是元学习。
简单说说元学习
元学习的目标在于训练出具有强自适应性的模型,这种模型可以在少数样本下被训练来解决新的任务。因此,元学习也被叫做Learn to learn,即“学习如何学习”,根据以往的知识经验来指导在新任务上的学习。
元学习通常强调在新任务上样本量比较少,甚至只有一个训练样本。这两种情况分别对应于few-shot learning和one-shot learning(其实还有更夸张的zero-shot learning)。进行元学习的方法种类有很多,其中一种是基于预测梯度的方法。这里面最著名的一种算法是MAML(Model Agnostic Meta Learning),即与模型无关的元学习。
MAML的目标在于训练模型的初始参数使得其在一个新的任务中根据少量数据,通过一次或几次梯度更新后能够得到最优的效果。简单来说就是找到一个适合进一步微调的初始参数。作者提出的方法是通过最小化模型参数在不同任务下单步更新后的参数分别在各自任务中的损失总和,来确定最终参数。最小化的方式也是采用梯度下降,即每步计算总体损失相对于参数的梯度,并进行梯度更新。由于某个任务下的参数本身还要进行一次梯度下降,因此这里会计算损失的二阶梯度,即Hessian矩阵。下面是MAML的算法流程[1]:

元学习和联邦学习的关系是什么
说实话,尽管我在两年前就接触过元学习,但是当我第一眼看到利用元学习进行个性化联邦学习的时候首先的反应还是:“这两个有啥关系?”不过阅读完Improving Federated Learning Personalization via Model Agnostic Meta Learning这篇文章之后,你就会惊奇的发现:
这两个竟然是一回事?
或者更准确的说,联邦学习中最常用的FedAvg算法本质上也是一种MAML算法,是不是很神奇?下图左侧是FL和MAML的一个统一流程,中间是一种叫Reptile的MAML算法流程,右侧是FedAvg的算法流程。可以看到,MAML中的内层循环就对应于FedAvg中的参与方本地更新,而外侧循环则对应于FedAvg的全局更新,并且两种更新分别是基于本地数据的单步或多步梯度下降以及基于全局参数的单步梯度下降。从更高层面来说,MAML的目的在于找到一个合适的参数,使得其对于某个新的任务进行微调时能够在尽可能少的更新后得到一个比较好的结果;而对于个性化的FL来说,我们希望得到的全局模型在本地数据上进行微调后也可以很快得到良好的个性化模型,因此,这两种算法从本质上来说也是共通的。

上面提到了另一种MAML算法——Reptile,我们在附录中简单做个介绍,如果想深入了解可以直接阅读原文。下面回到FedAvg和MAML的对比,在经过一番推导之后可以得到:
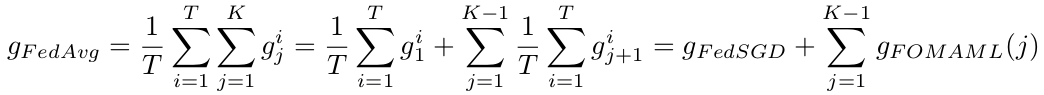
FedAvg算法相当于是一系列在多轮本地更新后进行个性化效果优化的算法的线性组合。简单来说就是FedAvg相当于是FedSGD(即本地进行一次SGD)加上多个FOMAML(且本地迭代轮数K不同)。当然,这不等于说FedAvg的优化目标也是这些算法的优化目标的线性组合。在后续的实验中作者发现当K=1时,模型很难进行个性化;当K越大时,模型的个性化效果越好;但是当K超过某个值之后,初始模型的效果开始变得不稳定。
注:这里的FOMAML是指First Order MAML,具体可以见MAML的论文。
将FedAvg看作是一种MAML算法给联邦学习的研究提供了一种新的思路,即如何将元学习中已有的经验应用到新兴的联邦学习研究中来,相信将来也会有更多这方面的研究。
基于元学习的个性化联邦学习算法
了解了元学习和联邦学习之间的关系后,我们来看看现有的一些基于元学习的个性化联邦学习是怎么做的。这里参考了三篇文章,分别是:
- Improving Federated Learning Personalization via Model Agnostic Meta Learning
- Personalized Federated Learning: A Meta-Learning Approach
- Federated Meta-Learning with Fast Convergence and Efficient Communication
第一篇文章给出的算法叫Personalized FedAvg,从名字上也能看出是基于FedAvg的一种修改,其具体流程如下:

首先进行多轮FedAvg操作,其中本地epoch的次数E要设置的大一些,这是因为作者发现采用比较大的E能够得到效果更好的personalized model(不能太大,否则initial model的效果会变差)。其次对FedAvg的全局模型(这里叫initial model)继续通过Reptile进行微调,这里的K是本地step的个数。最后再在本地进行微调。
个人感觉这篇文章最大的一个问题就是作者并没有详细说明为什么要进行这三步,而是更多的给出在进行这三步时的一些tips。当然本文还是得出了一些有趣的结论,例如“本地多次迭代可以改善个性化模型的效果”以及“训练一个总体效果好的全局模型并不代表也会得到好的个性化模型”。这些发现都对之后的研究有一定的指导性帮助。
第二篇文章提出的Per-FedAvg和第三篇文章提出的FedMeta都是在FedAvg的框架下对本地训练和全局更新部分进行基于MAML算法的调整。Per-FedAvg的算法流程如下:

这里假设个性化是指在本地进行单步更新(和优化目标相关,分析起来相对简单一些),经过一步步推导就可以得到最内侧循环的公式(k表示参与方编号,t表示本地训练的迭代轮次)。对MAML比较熟悉的朋友会发现这基本就是MAML论文中给出的更新方式,区别在于:
- 单步更新是单步mini-batch SGD
- 用了三个不同的本地batch数据分别计算两个梯度和一个Hessian矩阵
另外还要注意的是,这两步更新都是在本地做的,全局的更新和FedAvg类似,但是是普通平均而不是加权平均。
FedMeta的算法流程如下:

作者给出了统一框架下的两种算法ModelTrainingMAML和ModelTrainingMetaSGD,分别在固定学习率和自适应学习率的情况下进行训练。和Per-FedAvg类似,这里本地模型更新也是通过MAML的方式进行,只不过计算的是梯度。另外在全局参数更新时也是对所有梯度进行平均,和Per-FedAvg相似。当然,传模型和传梯度本质上还是不太一样的,另外FedMeta的episode循环在最外围,本地只进行单步更新(这也是为什么传的是梯度而不是模型),这两点也是这两种方法最大的不同。
小小的总结
可能是因为基于元学习的个性化联邦学习研究仍然处于一个前期阶段,也可能是因为元学习和联邦学习的优化算法本身很接近,你会发现大家的做法其实都比较类似,更多是一些细节上的差异。不过在我第一次认识到FedAvg本质上就是一种MAML算法时还是很“震撼”的,这其实也说明了机器学习各个领域的紧密联系,很可能打开A门的钥匙也能够打开B门的锁,多了解一些其他相近领域的知识还是很有用的。希望将来自己也能积累更多的知识吧,争取早日触类旁通。
附录
Reptile简介
Reptile和MAML的区别在于它合并了内外循环(也可以理解为内循环的迭代次数为1),也因此将MAML中的两次求导简化为这里的一次(即循环内第二步的本地迭代)。最后一步不是简单地朝着 $\widetilde{\phi} - \phi$ 的方向更新,而是将它看作是一个梯度,并采用一种例如Adam这样的自适应算法来进行更新。下图是完整的算法流程:

MAML和Reptile有点类似于GD和SGD,一个是向着全体任务空间极值点的方向更新,而另一个则更具有随机性,但是总体方向还是一致的,并且通过Adam这样的方法来自适应地调整其更新速度与方向。上面采样任务的步骤中也可以同时采样多个任务(方便分布式计算),最后的更新也修改为(类似于SGD到mini-batch SGD):
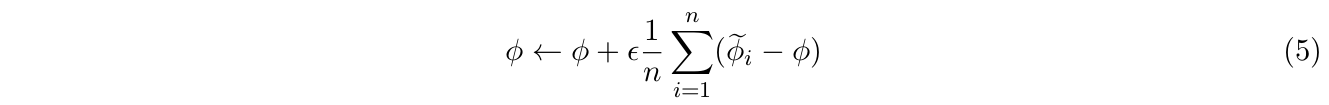
这里的二阶导降为一阶导可以理解为把内外层参数割裂开,即导数的导数(二阶导数)转化为两次不相关的求导(即一阶导数)。
Reference
[1] Finn C , Abbeel P , Levine S . Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks[J]. 2017.
[2] Jiang Y , Konen J , Rush K , et al. Improving Federated Learning Personalization via Model Agnostic Meta Learning[J]. arXiv, 2019.
[3] Nichol A, Schulman J. Reptile: a Scalable Metalearning Algorithm[J]. arXiv: Learning, 2018.
[4] Fallah A, Mokhtari A, Ozdaglar A, et al. Personalized Federated Learning: A Meta-Learning Approach[J]. arXiv: Learning, 2020.
[5] Chen F, Luo M, Dong Z, et al. Federated Meta-Learning with Fast Convergence and Efficient Communication[J]. arXiv: Learning, 2018.