简介
今年的ICLR2020中一共收录了7篇与联邦学习相关的文章,其中2篇是演讲的文章5篇是poster-paper,具体收录的论文标题可以看机器之心的这篇文章。这里主要介绍一下其中的三篇,其他几篇就简短地过一下。
FAIR RESOURCE ALLOCATION IN FEDERATED LEARNING
第一篇文章来自CMU和FB的合作,聚焦联邦学习中的公平性问题。这里的公平问题是指在联邦学习中由于各个参与方的数据分布不同,联合训练的结果很容易导致最终的模型对于某个参与方下数据的效果比另一个参与方的要好,即所谓的“不公平”。我个人觉得公平性还是很重要的,因为这直接决定了参与方的参与热情。不过这也牵扯到一个最核心的问题,那就是——什么是公平?
文章中对于公平的定义是这样的:
对于训练的模型$ w $和$ \tilde{w} $,如果模型$ w $在$ m $个设备上($ a_1,\dots,a_m $)的效果相比于$ \tilde{w} $在同样$ m $个设备上的效果更平均(uniform),那么我们就认为模型$ w $提供了一个相比于模型$ \tilde{w} $更公平的解决方案。
简单来说,就是在保证整体效果的前提下,尽量使得各个参与方之间的收益平均(方差较小)。上面的前提主要是因为作者发现公平和整体效果(这里用平均收益表示)之间有一丝矛盾。
上面提到了作者希望保证联邦学习的公平,并给出了公平的定义。那么下面就要解决两个问题(也是本文的两个最大的创新点):如何设计一个“公平的”目标函数以及如何针对这个函数进行优化。传统的目标函数(或者说FedAvg针对的目标函数)如下图所示:
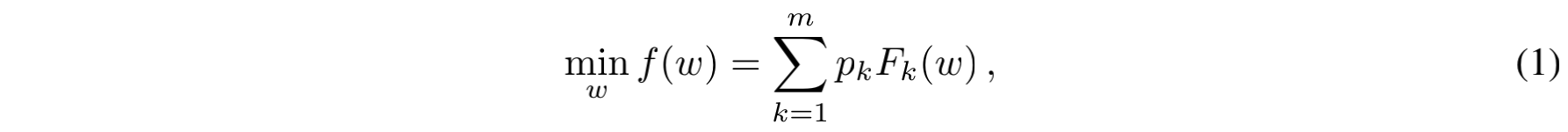
式子中的$ m $表示$ m $个设备,$ p_k $表示权重,一般设置为$ \frac{n_k}{n} $,即本地样本数量除以总样本数。$ F_k(w) $是所有本地样本上的经验风险。作者在此基础上进行了修改,提出了q-FFL:
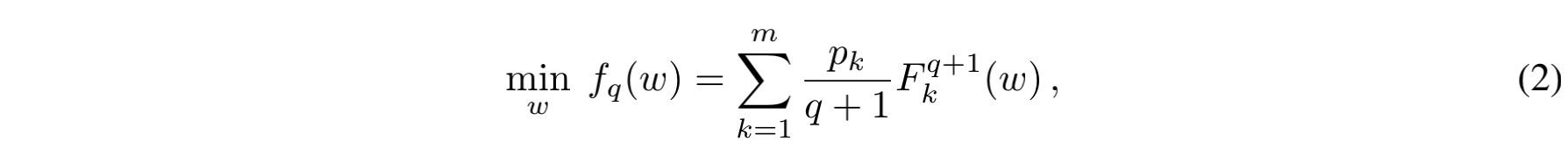
其中$ q $是一个大于0的超参数,$ F^{q+1}_{k} $表示$ F^k $的$ q+1 $次方。当$ q=0 $时,式(2)就退化为式(1)。当$ q $越大时,整体的优化目标就越偏向那些本地经验风险较大的设备。
此外,针对FedAvg作者也提出了其对应的改进版q-FedAvg。q-FedAvg的原理相对比较复杂,这里就简单给出其优化过程:

下面来说说这篇文章的一些局限性。我认为主要有两个,第一个就是什么才是所谓的公平?由于每个参与方本身提供的数据的数据量和数据质量就是不同的,我们其实不应该简单地让总体模型在各个参与方的数据上有着尽量平均的效果。一种显得更合理的方法是先评估各个参与方的贡献度,再由贡献度来分配收益。不过这可能又引发对小数据量参与方的歧视,而与联邦学习本身的理念背道而驰,因此如何设计一个靠谱的贡献度计算方式尤为重要。
另外超参数$ q $的选择也是一个问题。按照作者的说法,可以先选择几组$ q $分别进行训练,然后对比各组$ q $对应的效果和公平性,并从中做一个取舍。但是在实际应用中,这种方式显得效率很低,并且很难达成共识。有没有更好的做法,或者有没有什么方法能够摆脱$ q $这种超参数值得进一步研究。
不过总体来说这篇文章还是提醒了大家联邦学习中公平的重要性,并且给出了一个不错的思路,期待后续的研究进展。
FEDERATED LEARNING WITH MATCHED AVERAGING
第二篇文章针对联邦学习框架下现今常用的深度学习模型(例如CNN和LSTM)提出了一个更合适的优化方法FedMA(federated matched averaging)。它不仅让深层CNN和LSTM的模型取得了更好的效果,也减少了总体的通信开销。
这篇文章总体上来说是BBP-MAP从MLP向CNN和LSTM的一个扩展,看上去还蛮有意思的。不过由于我还没看过BBP-MAP,因此这里先挖个坑,等看完BBP-MAP再回来填上。
ON THE CONVERGENCE OF FEDAVG ON NON-IID DATA
第三篇文章可以简单理解为FedAvg的收敛性分析,给出了一些挺有意思的结论。
首先是对FedAvg收敛性的证明。作者证明了FedAvg的收敛率(convergence rate)是$ O(\frac{1}{T}) $,其中$ T $是每个设备进行SGD的总次数。和以往的收敛性证明不同的是,本文的收敛性证明中不需要以下两个很强的前提假设:数据IID以及所有设备保持连接。上述两个假设在联邦学习的场景下往往是不成立的,因此抛开这两个假设的理论分析会相对更贴近实际。
当然,任何的收敛性证明总归需要一定的前提假设。对于本文来说,其前提假设一共有四条,其中前两条都是针对的本地的目标函数F,需要足够“光滑”和“凸”:

后两条设定了每个设备内的随机梯度的方差界限以及其本身大小的界限,具体如下:

除此之外,作者还令$ \Gamma = F^\star - \sum_{k=1}^{N}{p_k}F^{\star}_{k} $来表示non-iid的程度,其中$ F^\star $表示目标函数最小值,$ N $表示设备总数,$ p_k $表示设备$ k $的权重。之后作者对所有设备参与和部分设备参与时的收敛性进行了计算,这里就不罗列具体的公式了,有兴趣的朋友可以阅读论文原文。
第二个有意思的点是对于某个固定的准确率$ \epsilon $,总的通信次数的复杂度满足:
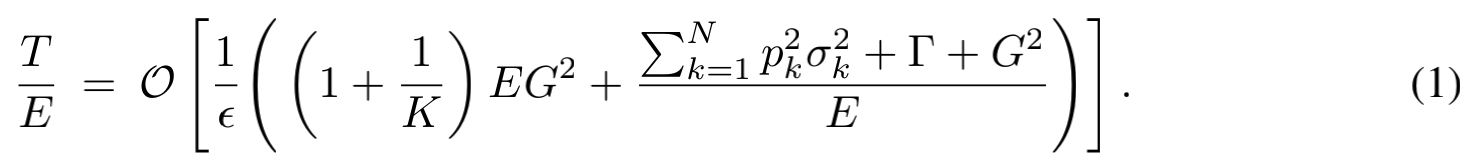
其中$ E $是每次通信前本地运行的SGD次数,$ K $表示每轮迭代的设备最少参与数量,其他几个符合的含义前文都有提到。从上面的式子中我们可以得到一个结论:E设置得太小或太大都会导致收敛性变差。另外,K的大小设置对收敛率的影响相对较小,因此我们可以将K/N的大小设置得小一些。
除此之外,每轮迭代中对设备的采样方法也会导致收敛性变化。作者提出了一种新的采样方式,可以让FedAvg的收敛率在非IID的情况下达到$ O(\frac{1}{T}) $,而原始的方法则无法保证。这种方法就是根据$ p_k $有放回地对设备进行采样。不过真实场景下,我们很难这样做,因为它的前提是我们必须对所有设备都有控制权(这样才能以某种概率进行采样)。
最后一个结论是当E>1时,学习率的衰减是必要的。如果学习率固定为$ \eta $,那么FedAvg最终收敛到的解将至少偏离最优解$ \Omega(\eta(E - 1)) $。不过衰减学习率会导致需要更多的训练轮数,即更多次的通信。从某种程度上说这和FedAvg的设计初衷相悖,因此实际运用时也需要很谨慎。遗憾的是,这篇论文里面并没有给出一个很好的指导(即如何进行衰减)和论证。在实验部分,学习率衰减的方式是$ \eta_t = \frac{\eta_0}{1+t} $。
最后总结一下,这篇文章告诉我们:
- FedAvg的收敛率是$ O(\frac{1}{T}) $,其中的前提假设见前文部分。
- E设置得太小或太大都会导致收敛性变差。
- K的大小设置对收敛率的影响相对较小,因此我们可以将K/N设置的小一些
- 每轮迭代中对设备的采样方法也会导致收敛性变化。
- 当E>1时,学习率的衰减是必要的。
不过对于上述的某些问题,其实作者也没能给出一个很好的解决方案,而且整个问题设定局限于目标函数为凸函数的情形下,因此还有待后续的进一步研究。
其他几篇文章
「GENERATIVE MODELS FOR EFFECTIVE ML ON PRIVATE, DECENTRALIZED DATASETS」来自谷歌团队,主要针对联邦学习场景下数据无法进行人工检查的问题(这里的检查是指判断标签的正确性或找出异常点等)。这篇文章提出用联邦学习场景下训练的GAN(采用差分隐私保证数据隐私)来对常见的数据问题进行检查。看上去还蛮有意思的,将来可以详细看看。
「DBA: DISTRIBUTED BACKDOOR ATTACKS AGAINST FEDERATED LEARNING」这篇文章的研究针对的是联邦学习的攻击模式。后门(backdoor)攻击的目的是通过注入敌对触发器(adversarial triggers)来操纵训练数据的子集,使得在被篡改数据集上训练的机器学习模型在嵌入相同触发器的测试集上会得到任意(方向)的错误预测。本文对以往中心化的后门攻击进行了改进,提出了一种分布式的后门攻击方式,即每个恶意参与方的敌对触发器不同,但是最终的攻击效果却更好。这种后门攻击在多设备的场景下是有可能发生的,不过在少量参与方参与的场景下发生的可能性较低。
「FEDERATED ADVERSARIAL DOMAIN ADAPTATION」这篇文章讲得是如何在联邦学习的框架下进行无监督域适应。在联邦学习中,不同参与方的数据的域(domain)很可能不同,因此联邦学习中训练得到的模型仍然可能因为域漂移的问题而无法泛化到新的设备。本文就是要解决这一问题,把对抗适应(adversarial adaptation)技术推广到联邦学习场景下。我本人对于域适应这块了解甚少,而且文章的问题设定也有点奇怪(一般来说不会是无监督),所以这篇文章就暂且先放下了。
「DIFFERENTIALLY PRIVATE META-LEARNING」在元学习中加入差分隐私进行隐私保护,并且提出了一种相对宽松的隐私机制——task-global privacy,相比于 local privacy模型效果会好很多。有兴趣的朋友可以继续深入研究一下。
References
[1] Li, Tian, et al. “Fair Resource Allocation in Federated Learning.” international conference on learning representations (2020).
[2] Wang, Hongyi, et al. “Federated Learning with Matched Averaging.” international conference on learning representations (2020).
[3] Li, Xiang, et al. “On the Convergence of FedAvg on Non-IID Data.” international conference on learning representations (2020).
[4] Augenstein, Sean, et al. “Generative Models for Effective ML on Private, Decentralized Datasets.” international conference on learning representations (2020).
[5] Xie, Chulin, et al. “DBA: Distributed Backdoor Attacks against Federated Learning.” international conference on learning representations (2020).
[6] Peng, Xingchao, et al. “Federated Adversarial Domain Adaptation.” international conference on learning representations (2020).
[7] Li, Jeffrey, et al. “Differentially Private Meta-Learning.” international conference on learning representations (2020).
[8] Yurochkin, Mikhail, et al. “Bayesian Nonparametric Federated Learning of Neural Networks.” international conference on machine learning (2019): 7252-7261.