简介
在今年的AAAI2020中,共有三篇和联邦学习相关的文章,他们分别是FedVision,Robust Federated Training via Collaborative Machine Teaching using Trusted Instances以及Practical Federated Gradient Boosting Decision Trees。
FedVision
先来看FedVision。Fedvision是微众银行和极视角联合开发的一个机器学习工程平台,支持CV领域的联邦学习应用发展。其目的在于让更多对联邦学习不了解的CV算法工程师也可以基于此开发CV应用,例如智慧城市中基于计算机视觉的安防。按照作者的说法,这套系统已经实际运行了四个多月,并且效率越来越好。下面来看看FedVision的亮点有哪些。
FedVision从算法流程角度上来说就是简单地把中心化的横向联邦学习框架用在了CV领域,下面是它的workflow:
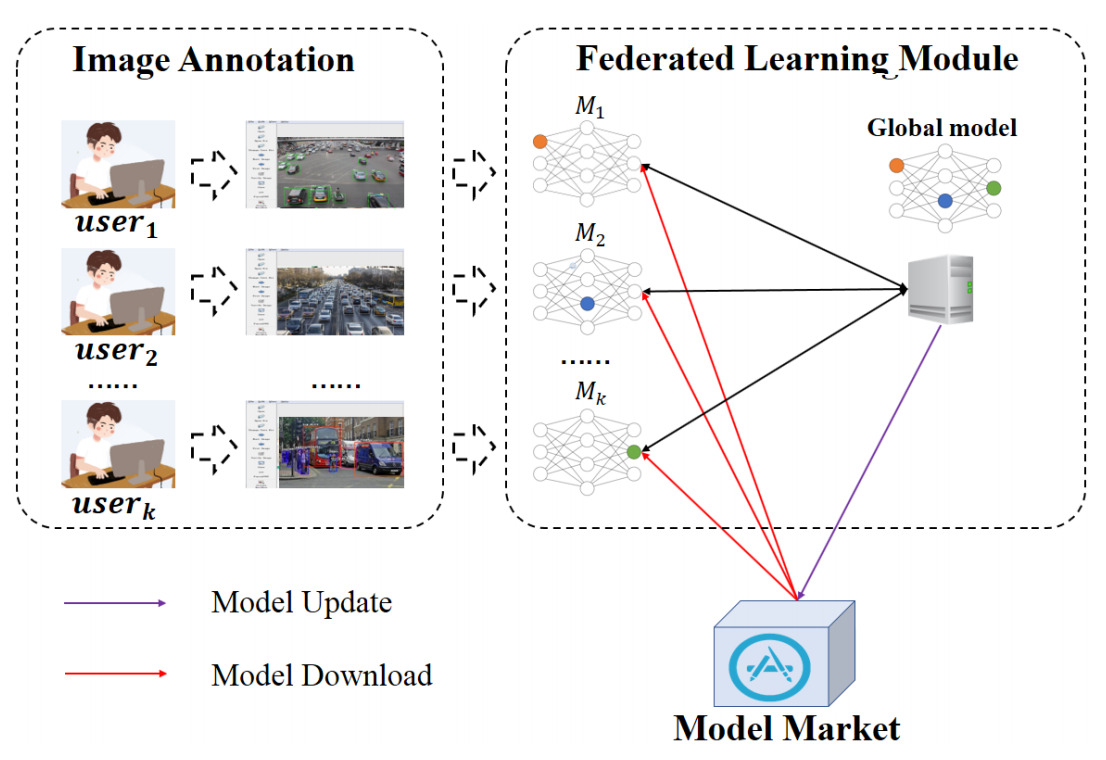
整体过程可以分为三步:(1)图像数据标注;(2)联邦模型训练;(3)联邦模型更新。图像标注没什么可说的,就很普通的图像标注功能。联邦模型训练的架构如下图所示:
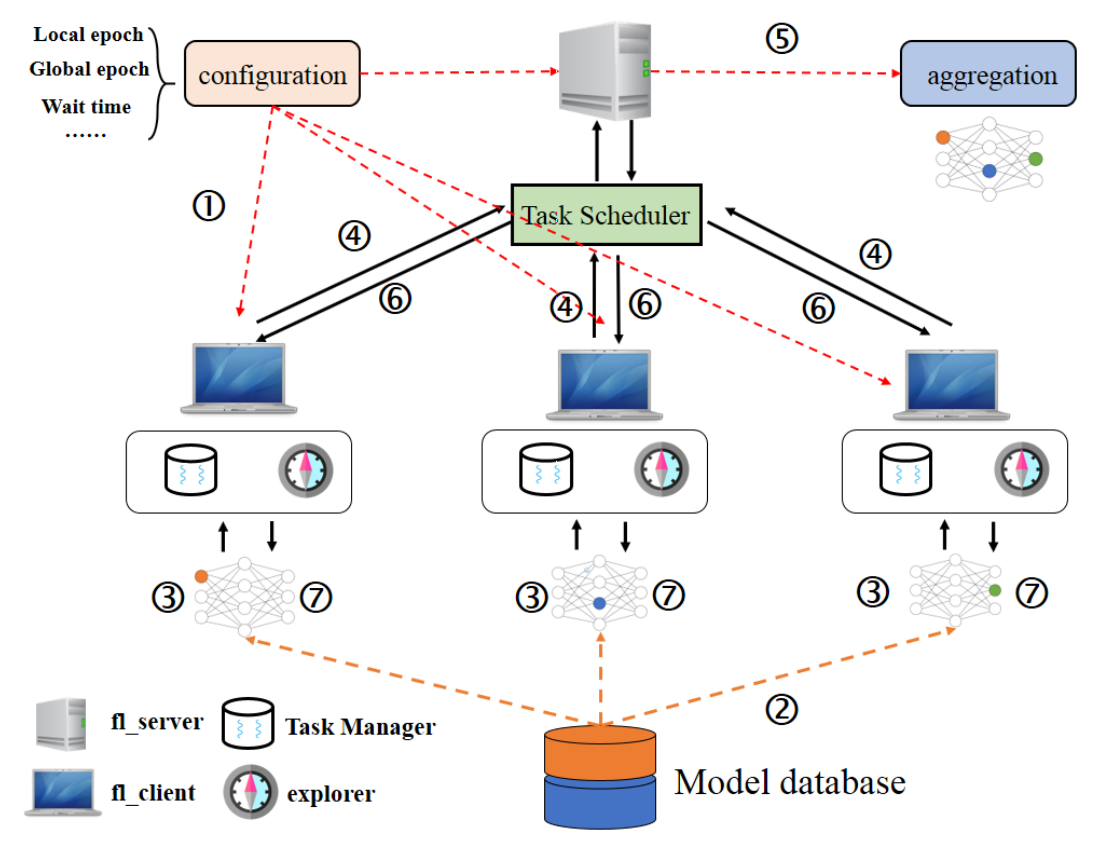
架构的设计也比较中规中矩,唯一的亮点可能算是Task Scheduler利用负载均衡的算法来平衡server和client的通信以及client本身的运算。第三步的模型更新也没有什么新意,就是工程上利用 Cloud Object Storage (COS)来存储中间模型(中间模型的数量可能越来越多)。
由此可见,从框架角度FedVision的创新有限。那么从算法角度来看,FedVision有没有提出什么有趣的点呢?首先,Fedvision提出了YOLOv3的联邦学习版本FedYOLOv3,不过它其实就是YOLOv3+FedAvg。。。其次,FedVision采用了一种模型压缩算法来对模型进行压缩,从而减小传输带宽。不过这个模型压缩算法也是Bengio和LeCun在2016年提出的老方法。
最后总结一下,本文从总体上来说没什么新意,可能就是第一个吃螃蟹的人吧。可以参考借鉴的地方在于:(1)系统框架:还是比较简洁和清楚的;(2)模型压缩:深度学习的模型还是要在压缩后进行传输。
Robust Federated Training
这篇文章主要想解决的问题是让联邦学习不再那么容易受到参与方本地数据中噪声的干扰,从而提升整体训练的鲁棒性。在传统的联邦学习中,某一个参与方内如果存在受到噪音损害的数据,就可能使得整个模型有偏。更进一步,如果某个参与方是恶意的,那么它可以通过data-poisoning的方式来破坏整个训练过程。因此,这确实是联邦学习中的一个痛点。
作者提出了一个联合机器教育(Collaborative Machine Teaching,CoMT)的解决办法。在CoMT中,本地的参与方充当老师,而中心服务器充当学生,由所有老师“联合执教”。也就是说,本方法可以看做是传统Machine Teaching方法,例如Super Teaching和DUTI(Debugging Using Trusted Items)在联邦学习框架下的一种扩展。在CoMT的设定中,本地数据内有一小部分是可信任的,由领域专家来认证。数据中的噪声可能会影响数据的标签,也可能影响数据的特征。
文章中对CoMT的过程进行了详细地介绍,也给出了推导,这里就不做介绍了。个人感觉文章针对的这个痛点确实是联邦学习的一个“大问题”,不过作者给出的解决办法需要专家干预得到受信任样本,从形式和效果上还是有点理想化,有待后续的研究改进。另外这篇文章虽然提到了data poisoning,却并没有办法解决这一问题。不过总体上来说这篇文章还是该领域一个不错的尝试,以后有时间可以再细究一下其算法原理。
Practical Federated Gradient Boosting Decision Trees
本文是针对横向联邦学习框架下的GBDT[注1]训练模式的一种改进,让其更具实用性(practical)。这里的实用性主要是指降低了训练过程中由加密措施带来的开销。它摒弃了传统的秘密共享、同态加密以及差分隐私的加密方式,而是转而寻找一种没有那么严密(可能会泄露参与方数据的部分信息),但是又不会让非诚实参与方获取到其他参与方原始数据的加密方式。
注1:文章中的GBDT其实是指XGBoost。
文中给出的方法叫SimFL,主要分为两步:
- 预处理阶段:对于每个参与方,利用LSH(局部敏感哈希)得到其他参与方中的每个数据中在其本身的数据中对应的最为相似的数据ID。也就是说,因为每个参与方只知道自己的数据,所以这里其实就是用自己的数据来代理其他参与方的数据,从而估计整个样本集的样本分布。
- 训练阶段:利用加权梯度提升(Weighted Gradient Boosting,WGB)方法来构建决策树。具体来说,就是在某一轮迭代时先确定某个代表参与方,假设叫$ P_m $,之后先计算本地数据的梯度g和二阶梯度h。之后再根据预处理阶段得到的最相似数据表,找到其他某个参与方(例如$ P_i $)中每个样本所对应的$ P_m $的样本,并用$ P_m $中的样本进行替代来计算$ P_i $的本地梯度和二阶梯度。之后将各个参与方的梯度传递给$ P_m $,并进行总体梯度的计算以及树的更新。因此,这里的“加权”其实就是用当前参与方的本地样本来代替所有参与方的样本,不同样本的数量由原来的1会增加到现在的x(看有多少相似样本),就好像是权重一样。
下面是上述两步的示意图:
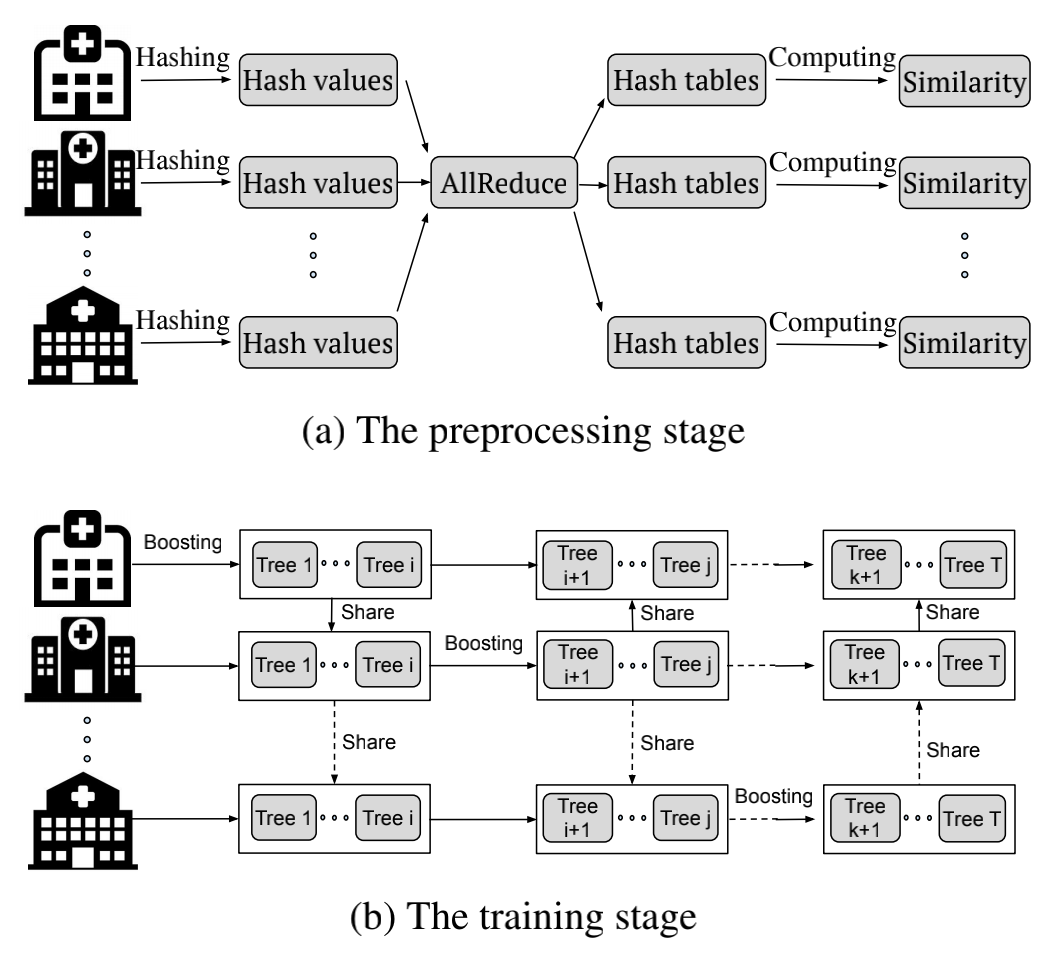
感觉这篇文章还是蛮有意思的,通过用本地数据代理全局数据来避免数据泄露。而且树模型本身就是一种离散模型,对于连续数值没有那么敏感,因此也比较适合用这种代理方式。从实验结果来看,效果还是不错的。
总结
这次AAAI2020的3篇有关联邦学习的文章分别针对三个方向:图像场景应用、增强鲁棒性和横向联邦学习算法研究。个人最喜欢第三篇文章,感觉树模型的横向联邦学习优化加速都可以采用类似的代理模糊策略,即用代理样本来近似进行建模。
References
[1] Liu, Yang, et al. “FedVision: An Online Visual Object Detection Platform Powered by Federated Learning..” arXiv: Learning (2020).
[2] Han, Yufei, and Xiangliang Zhang. “Robust Federated Training via Collaborative Machine Teaching using Trusted Instances..” arXiv: Learning (2019).
[3] Li, Qinbin, Zeyi Wen, and Bingsheng He. “Practical Federated Gradient Boosting Decision Trees.” arXiv: Learning (2019).