GRU是什么
GRU的全称是Gated Recurrent Unit,是一种相比LSTM更加简单的循环神经网络结构。由于上一篇文章中已经对LSTM的结构进行了介绍,因此这里直接先给出GRU的网络结构,然后我们再进一步探寻其效果背后的原因。GRU的网络结构如下图所示,这里引用了《神经网络与深度学习》中相关章节的图片:
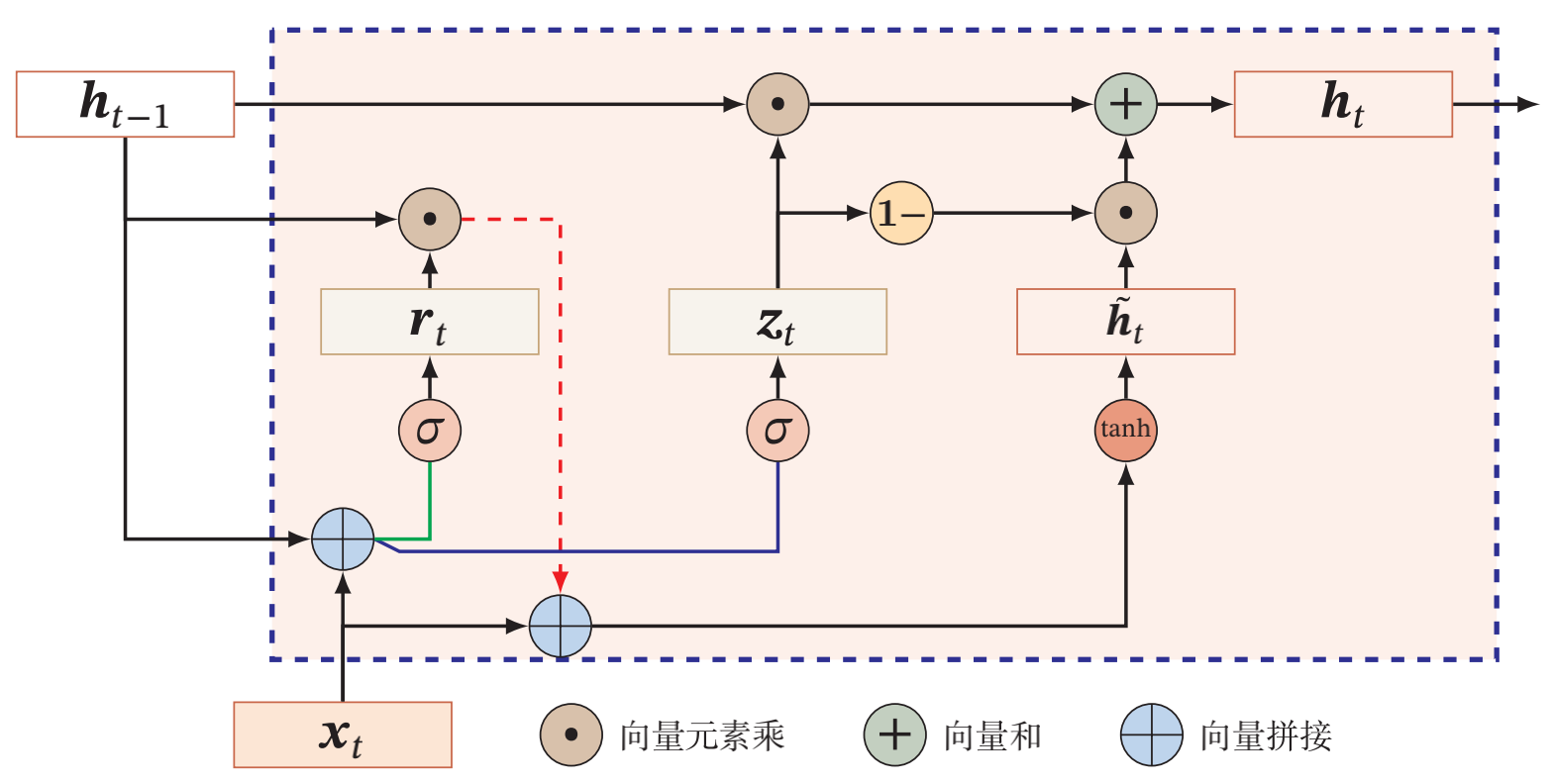
从图中我们可以看到,LSTM中的c和h被简化为只有h,并且门控的数量也从三个下降为两个(即图中的r和z),分别被称作重置门(reset gate)和更新门(update gate)。GRU的门控和LSTM的门控从结构上来说是一样的,都是将前一时刻的隐藏层输出和当前时刻的输入进行拼接后经过一个sigmoid函数得到门控端的结果(也就是这里的 $\textbf{r}_t$ 和 $\textbf{z}_t$ )。
门控原理
我们先来看重置门。重置门的门控端结果 $\textbf{r}_t$ 和其输入 $\textbf{h}_{t-1}$ ,经过点乘后与当前时刻的原始输入 $\textbf{x}_t$ 拼接后接入tanh函数,将各个元素映射到一个-1到1的区间内,得到当前时刻的候选状态 $\tilde{\textbf{h}_t}$ 。很显然,重置门的作用就是控制候选状态的结果。当 $\textbf{r}_t$ 结果为0向量时,候选状态就是 $tanh(\textbf{x}_t)$ ;当 $\textbf{r}_t$ 结果为1向量时,候选状态就是 $tanh(\textbf{h}_{t-1})$ 。因此当 $\textbf{r}_t$ 结果为0向量时,候选状态相当于被重置了,而结果为1向量时,候选状态退化为简单的RNN,所以这个门被叫做重置门。
下面看一下更新门。更新门的巧妙之处在于利用了sigmoid输出结果区间为0-1的性质,将原本的一个门拆分为互补的两个门,即 $\textbf{z}_t$ 和 $1-\textbf{z}_t$ ,分别对 $\textbf{h}_{t-1}$ 和 $\tilde{\textbf{h}_t}$ 的结果进行控制。当 $\textbf{z}_t$ 为0向量时, $\textbf{h}_{t-1}$ 被阻断,因此 $\textbf{h}_t$ 其实就是当前的候选状态,而上一时刻的隐藏状态 $\textbf{h}_{t-1}$ 被遗忘;当 $\textbf{z}_t$ 为1向量时, $\textbf{h}_t$ 转变为上一时刻隐藏状态的线性变换。可以看到,通过更新门我们同时完成了遗忘和记忆的操作。
对比LSTM
LSTM结构中存在三个门:忘记门、输入门和输出门,而GRU中只存在重置门和更新门。因此相比LSTM来说,GRU的结构更简单,参数更少,训练也更快。更具体地说,LSTM中c类似于GRU中的隐藏状态h,而LSTM中的h则类似于GRU中的候选状态 $\tilde{\textbf{h}_t}$ 。由此我们可以进一步类比两种方法的门控,LSTM中的忘记门和输入门类似于GRU中更新门的正负极(分别对应于 $\textbf{z}_t$ 和 $1-\textbf{z}_t$ ),而LSTM的输出门则近似于GRU中的重置门。不过这里存在时间差,即LSTM中t-1时刻的输出门近似于t时刻时GRU的重置门。这种类比还是很有意思的。
总结
GRU通过重置门和更新门达到了和LSTM相似的效果,并且拥有更少的参数量以及更快的训练和预测速度,因此在很多领域上相比于LSTM会更为常用。