论文简介
这篇文章可以称得上是深度推荐系统领域的一篇经典论文了。文章其实思路很简单,那就是利用FM和DNN分别构建低阶和高阶交叉特征,从而提升模型的效果。在此之上,作者还提出了一些细节上的优化,较少了模型的复杂度并提升了效果。不过就我个人而言,这篇文章的创新点似乎不是很多,更像是对前人工作的融合和改进。为什么这么说呢?我们先来看看这里的“前人工作”有哪些。
前人工作
- FM 第一个就是DeepFM里面的“FM”。简单来说就是通过将交叉项系数表示为对应特征的隐向量的内积来减少参数量和让训练更充分。DeepFM用到FM的原因主要在于其无需人工构建交叉特征以及可以比较好地处理稀疏特征的优点。
- FNN FNN我们前面也有讲过,这是一种将FM接入DNN的尝试。DeepFM主要借鉴的地方在于将原始特征看成一个个field,并且一个field对应一个embedding矩阵。相比于FNN,DeepFM主要改进的地方是抛弃了FM的预训练部分。
- PNN PNN本身就是对FNN的一种改进,通过引入Product层来进行vector-wise(定义参考xDeepFM)的特征交叉。DeepFM对Product层中的内外积部分进行了保留以构成FM部分。
- Wide&Deep Wide&Deep分为Wide部分和Deep部分。其中wide部分就是一个LR,不过输入特征需要进行人工构建;Deep部分就是一个DNN,两者拼接到一起通过sigmoid层做最后的分类。DeepFM借鉴了这种同时生成低阶和高阶特征的方式,并且在此之上做了两点改进:一是用FM部分替换Wide部分,从而不再需要人工构建交叉特征;二是让高阶和低阶部分公用embedding,进行联合训练。
网络结构
从上面的回顾也可以看出来,DeepFM相当于是将Wide&Deep中的Wide部分替换为FM,再参考FNN和PNN来实现FM部分。我们先来看看网络的总体构成:
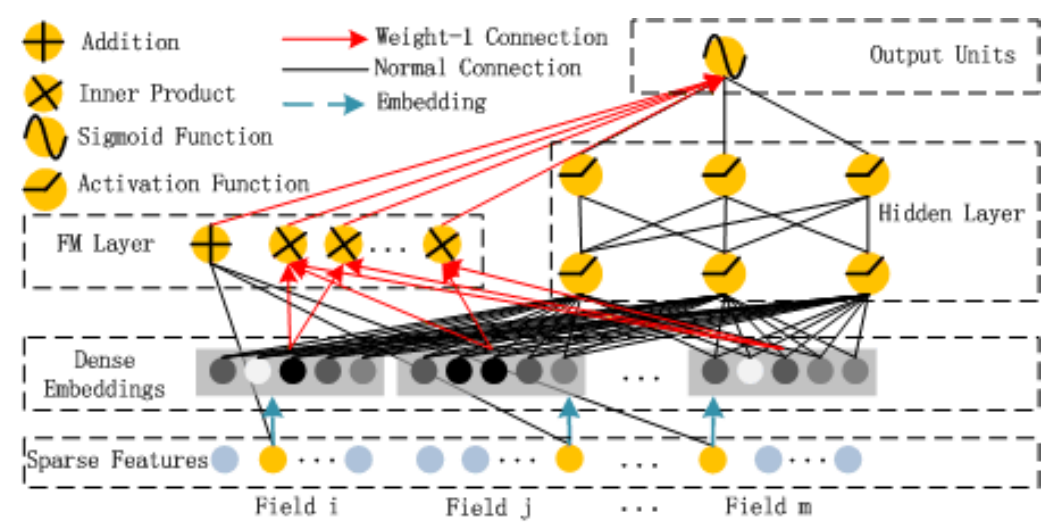
这个图还是画得很清楚的。最底下是原始特征和embedding层,其中embedding层是共用的。在此之上左边是FM层,右边是DNN层,最后将两者拼接并通过Sigmoid函数得到概率值。个人认为embedding共用算是DeepFM里面最大的一个创新点了,尽管这看上去比较简单,但是它事实上解决了多个问题:一是将低阶和高阶特征更紧密地结合到一起;二是减少了整体训练的复杂度;三是通过这种方式提升了网络的鲁棒性。不过从某种程度上来说,共用embedding其实也可以看做是权重共享在这个场景下的一种应用。
对于FM部分来说,其结构如下:
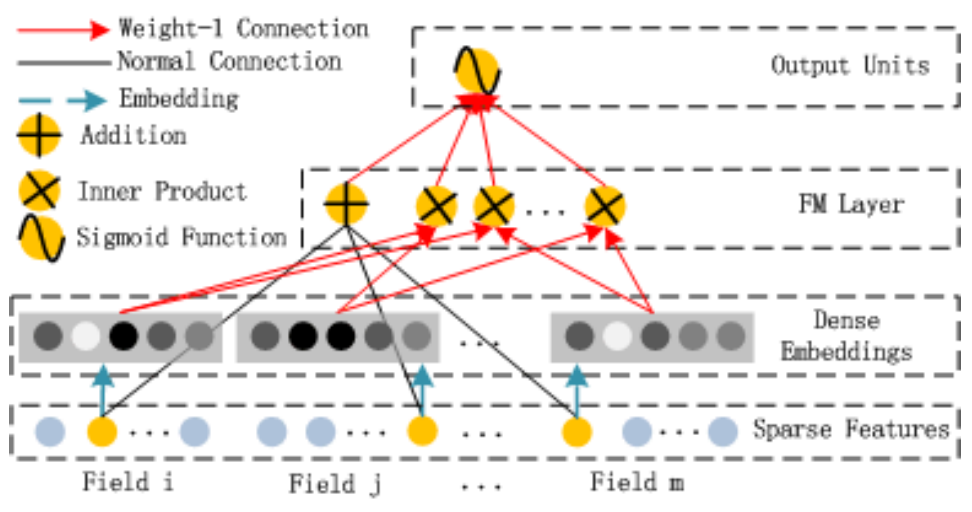
可以说FM层完全模拟了FM的表达式。另外要注意的是,这里的FM是vector-wise的,也就是说同一个field内的各项是不做交叉的。
DNN部分结构如下:
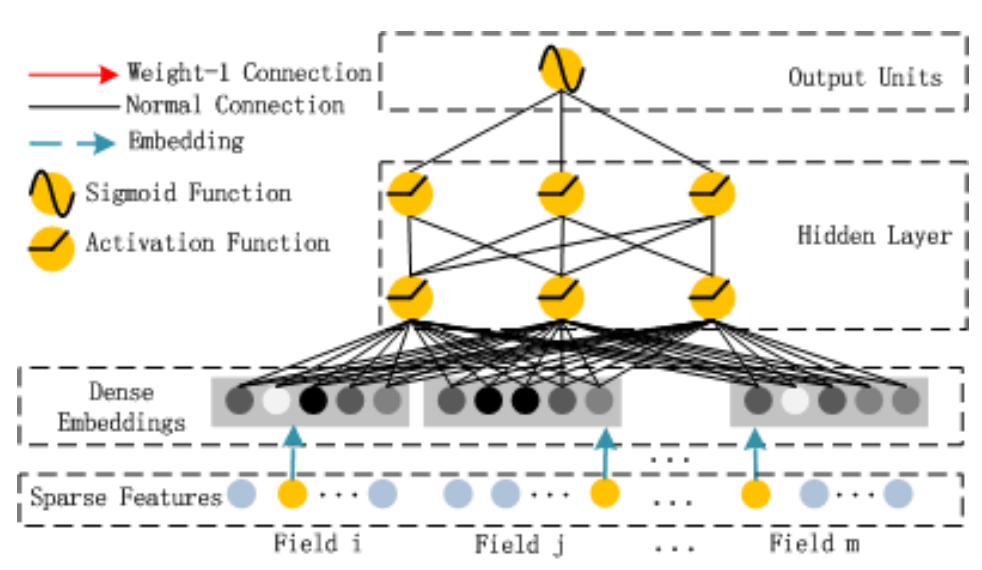
可以看到就是简单地embedding加全连接层。上面几张结构图中各种连线的详细解释如下图所示:

简单总结
总的来说,DeepFM更像是对于前人贡献的一种融合和改进,不过因为其结构简单,效率和效果都比较高,因此在工业界的运用还是比较多的。