论文简介
这篇论文[1]来自谷歌,算是做特征组合的文章中比较有名的,一般用在CTR预估中。
网络结构
正如文章标题所写,DCN可以分为深度网络(Deep Network)和交叉网络(Cross Network)两部分。深度网络就是一个简单的DNN,激活函数是ReLU;而交叉网络算是这里最大的一个创新点,用来生成高阶的交叉特征。我们先看一下论文中给出的网络结构图,再对它进行介绍。
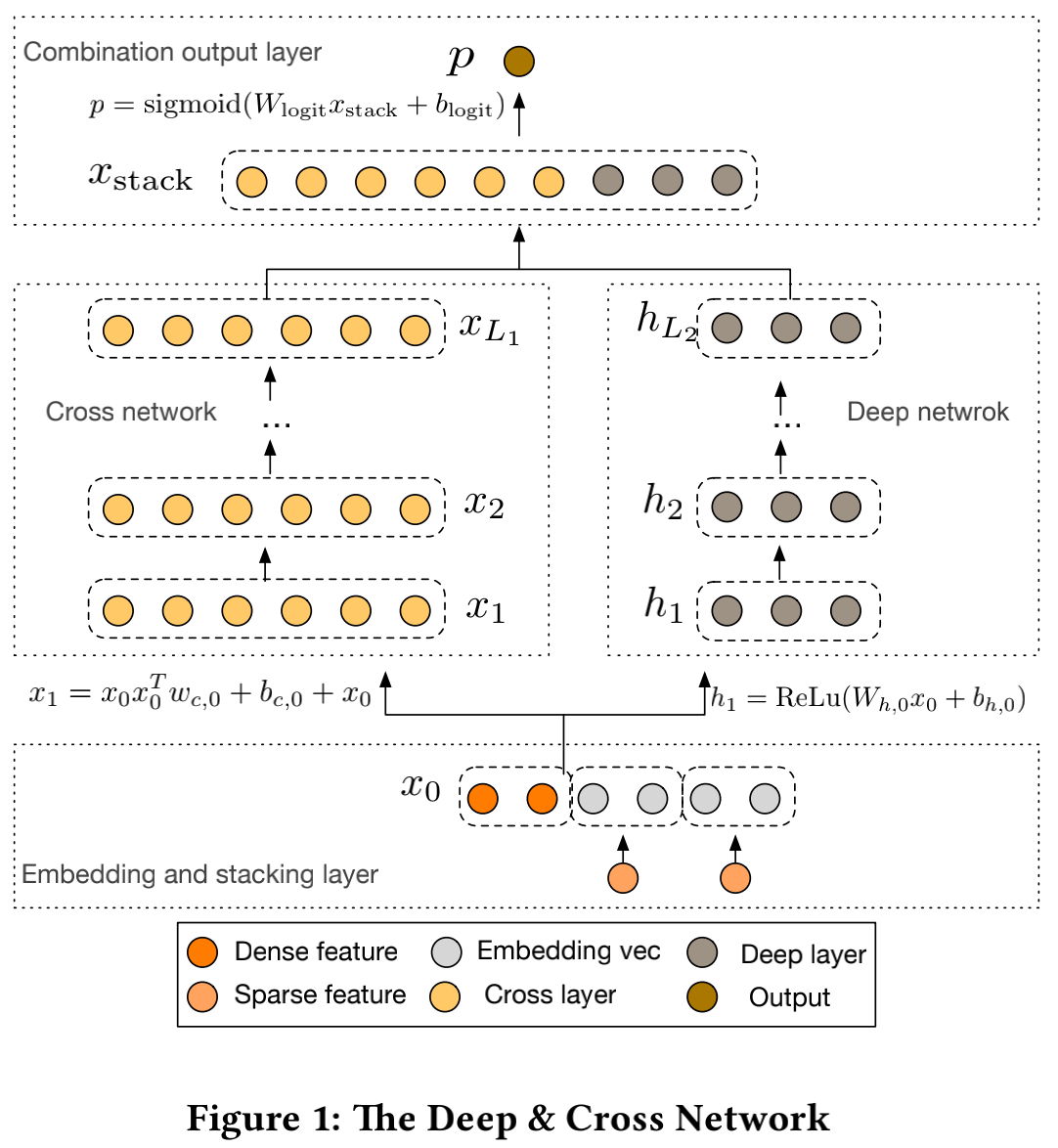
作者先将原始数据中的稀疏特征(即经过one-hot后的类别特征)做embedding,再将其与连续特征进行拼接。这一步的主要目的是通过embedding对稀疏特征进行降维。拼接后的结果作为深度网络和交叉网络的输入,即图中的x0。
交叉网络为一个多层结构,每层的输出结果的维度和输入是一样的。更新的公式如下图所示:
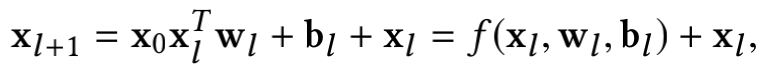
可以看到,第l+1层的结果其实是第l层的结果经过一个交叉特征生成函数f后再加上其原本的结果,也就是说交叉特征函数拟合的是两层之间的残差。一层交叉层的示意图如下:
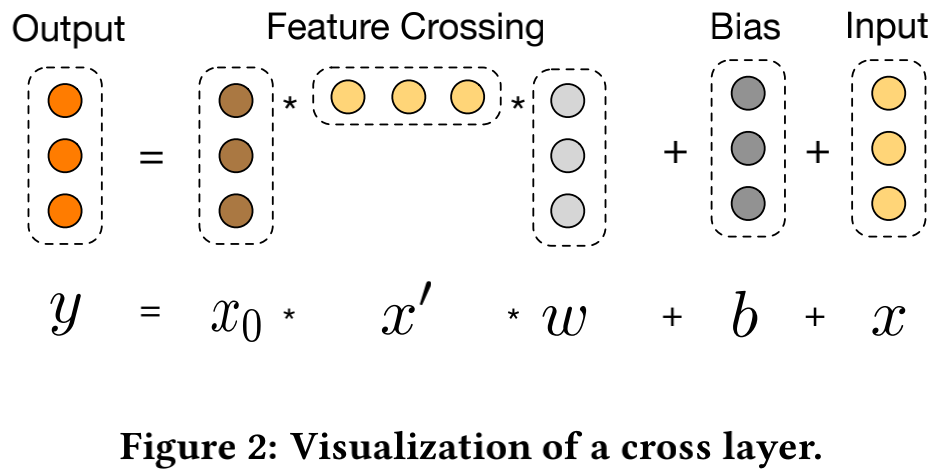
由于每一层中的参数只有W和b,而w和b的维度都是和x一样的(假设是d),那么如果交叉网络的层数为Lc,整个网络的参数量就是d*Lc*2,也就是说和输入维度呈线性关系。因此,相比Deep部分,交叉网络时间复杂度可以忽略不计,DCN整体的时间复杂度仍然和DNN是一样的。另外由于x0*xlT的秩为1(每一行都线性相关),所以我们没有必要存储整个d*d的矩阵来计算得到所有交叉项的结果。
为什么这么做
现在我们已经知道了网络结构是怎样的,那么为什么这么设计呢?我个人将其总结为几个问题,并给出了自己的理解。
Q:我们知道DNN本身可以自动生成高阶交叉特征,那么为什么还要在DNN的基础上引进Cross Network呢?
A:因为DNN只能隐式地生成所有交叉特征(你很难说具体生成了哪些,并且系数是多少),并且无法高效地生成和学习各种交叉特征。相比之下,交叉网络因其结构所致,可以更高效地学习固定阶数的交叉特征(bounded-degree feature interations)。
Q:那为什么有了交叉网络还要DNN呢?
A:因为交叉网络的参数量比较小,因此对模型的能力(capacity)还是有所限制。此外DNN不仅可以引入高阶交叉特征,还可以引入非线性,所以在交叉网络的基础上加入了并行的DNN。
Q:在交叉网络中,最后为什么要加上Xl?
A:这其实是借鉴了残差网络的思想,防止计算过程中出现梯度的弥散现象(扩展阅读:残差网络解决了什么,为什么有效?)。此外可能也是为了让参数训练更充分(较低阶的交叉项会影响多层参数)。
Q:交叉网络能生成多少交叉项?每个交叉项的参数都是不同的吗?
A:由交叉网络的公式可以推导出交叉网络中包含了所有阶数小于l+1的交叉项(如果一共有l层),并且它们的系数都是不同的。由于更新公式的右侧最后一项是xl,因此会引入一个阶数错位,从而导致所有交叉项都能被生成,并且参数不同(参数就是多参数中对应部分的和)。例如我们只考虑第一层和第二层,下图中l1表示第一层,l2表示第二层,f2表示第二层的交叉函数部分。里面的数字表示x的阶数。
1
2
3
f2 3 2
l1 2 1
l2 3 2 1
可以看到第一层包括一次项和2阶交叉项,经过f2后阶数加1,即产生3阶交叉项和2阶交叉项,两者求和后得到第二层的结果,包括1阶、2阶和3阶项,其中2阶项其实是两层参数的加权叠加。
和FM类似,通过这种参数共享可以使模型效率更高,鲁棒性更强,并且使得训练某个参数的数据更充分。
Q:DCN和DeepFM的区别是什么?
A:前面也说了,DCN的交叉网络部分和FM一样通过参数共享来提升效率和鲁棒性,并使得模型训练得更充分。不过交叉网络和FM最大的区别在于它支持更高阶数的交叉项,而不是像FM那样固定为2。这也是DCN和Deep-FM最大的不同。除此之外,DCN的embedding也和DeepFM略有不同,它的长度不是固定的,而是 6×(category cardinality)^1/4。
Reference
[1] Wang R , Fu B , Fu G , et al. Deep & Cross Network for Ad Click Predictions[J]. 2017.