Before All
在教程之前我想先说明一下通过本教程大家能学到什么。
这里说的“环境准备”是什么?
简单来说就是让你的电脑上能够运行Spark,并且可以构建依赖Spark的项目,例如自己做些小实验或者进行基于Spark的项目开发。当然,Spark本身是存在多种运行模式的,例如local、standalone和Spark on Yarn等等,那么这里说的是local模式的Spark,至于其他的模式看看之后有没有时间补充。
本人电脑的OS
本教程是基于macOS(macOS Mojave 10.14.6)的,在其他操作系统上类似但不完全相同。
我们要做些什么
在本教程中我们将完成以下几步:
- 下载并安装开发环境(这里是Intellij IDEA)
- 安装JDK
- 在IDEA安装Scala插件并下载安装Scala
- 新建一个Project并依赖Spark
- 写一个简单的小程序并运行 我会尽量详细地介绍上述几步,帮助大家更快地完成环境的搭建。
OK, let’s GO!
开发环境准备
开发环境的推荐和介绍并不在本教程的范围内,因此我这里就不对Intellij IDEA进行更多介绍了。我们直接进入正题:
下载和安装
打开Intellij IDEA的官网,点击页面中间的Download进入下载页面,之后选择Community版本进行下载即可。
这里注意选择和你电脑相同的操作系统的版本。不过网站会检测你的电脑操作系统版本,所以一般不用调整。
下载完成之后就可以点击安装,依照向导的指示即可。
安装JDK
进入Oracle的Java SE Downloads页面,选择合适的Java SE版本。我们这里选择Java SE 8u241:

点击页面中的JDK Download,进入下载页面。
这里需要先注册Oracle账号并登陆后才能下载。
下载会比较慢,需要耐心等待一段时间。
在IDEA中安装Scala插件并下载安装Scala
打开IDEA的Preference,选择Plugin,在搜索框中输入scala。如果未搜到任何内容,那说明还没有安装插件,这时需要点击下图中红框圈出来的Browse repositories进行搜索,同样还是输入scala:
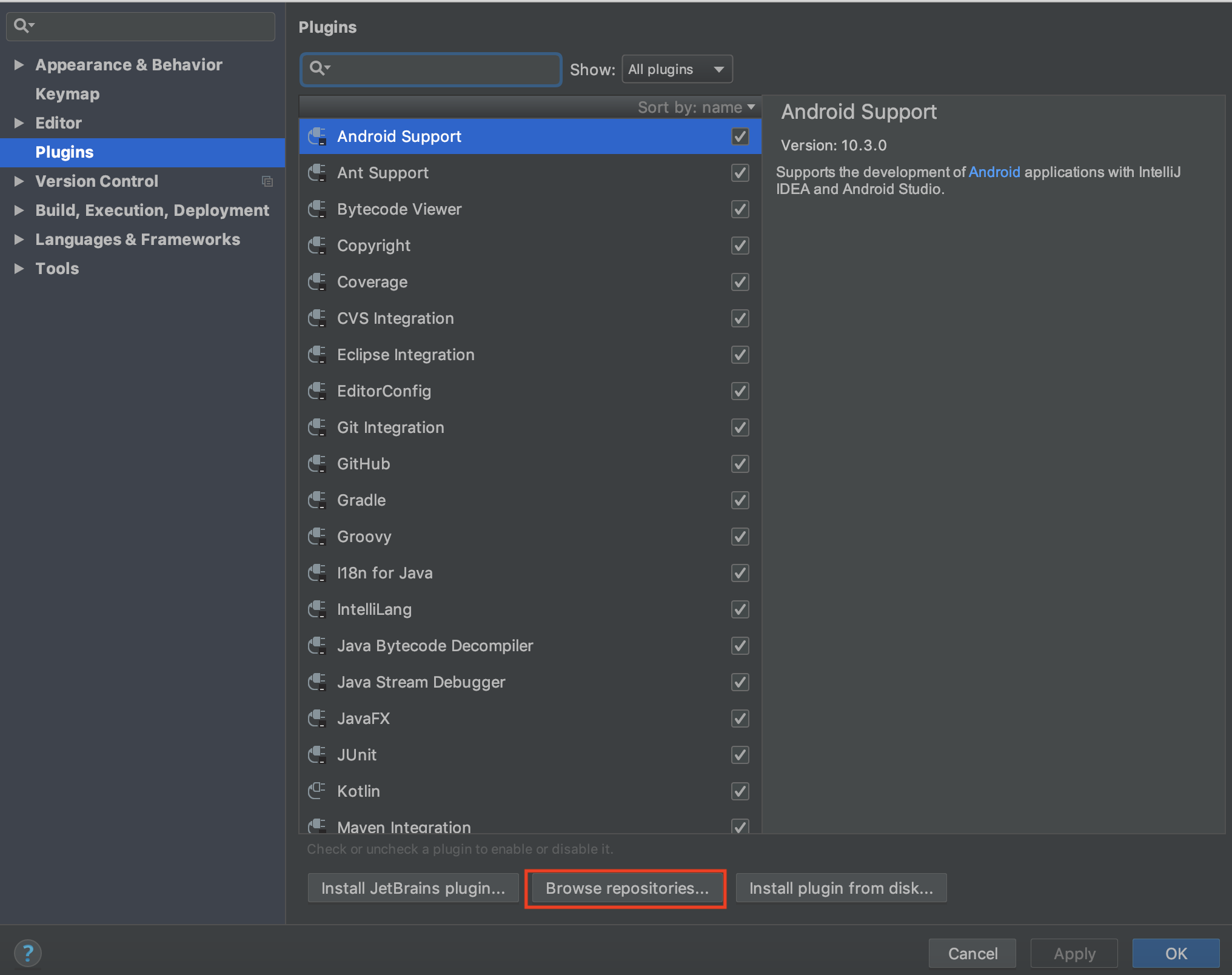
选择下图中的scala插件:
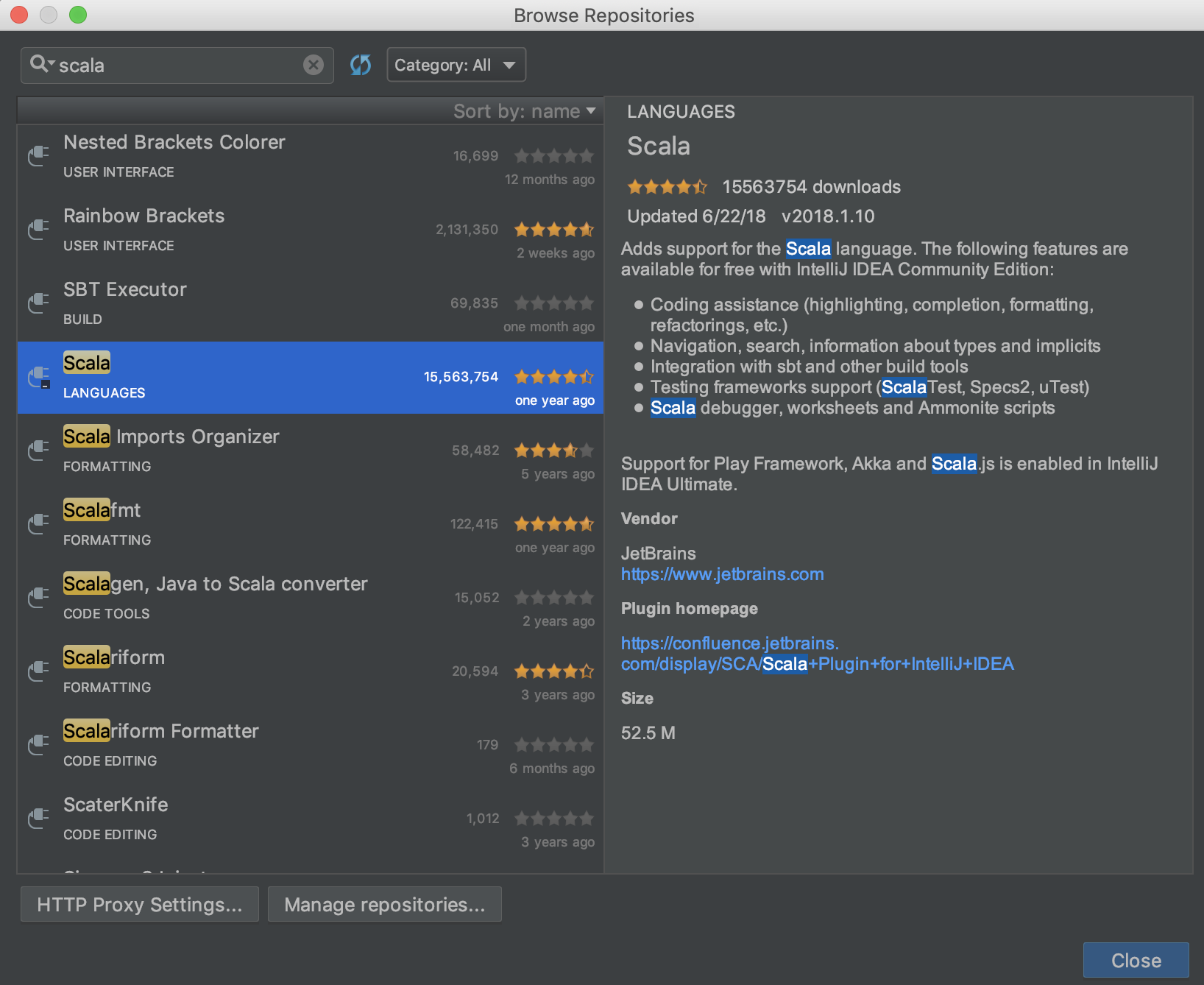
点击install进行安装。之后等待其安装完成即可。
下面就是安装Scala了。我们可以到Scala的官网上下载并手动安装scala,具体的操作可以参考这篇文章。Scala的版本选择2.11.12,因为Spark是用Scala 2.11编译的。
安装完scala之后可以通过在命令行输入scala进行验证:

新建一个Project并依赖Spark
新建项目
打开IDEA,选择新建Project,Project SDK部分应该会自动加载之前我们下载并安装好的Java SDK:
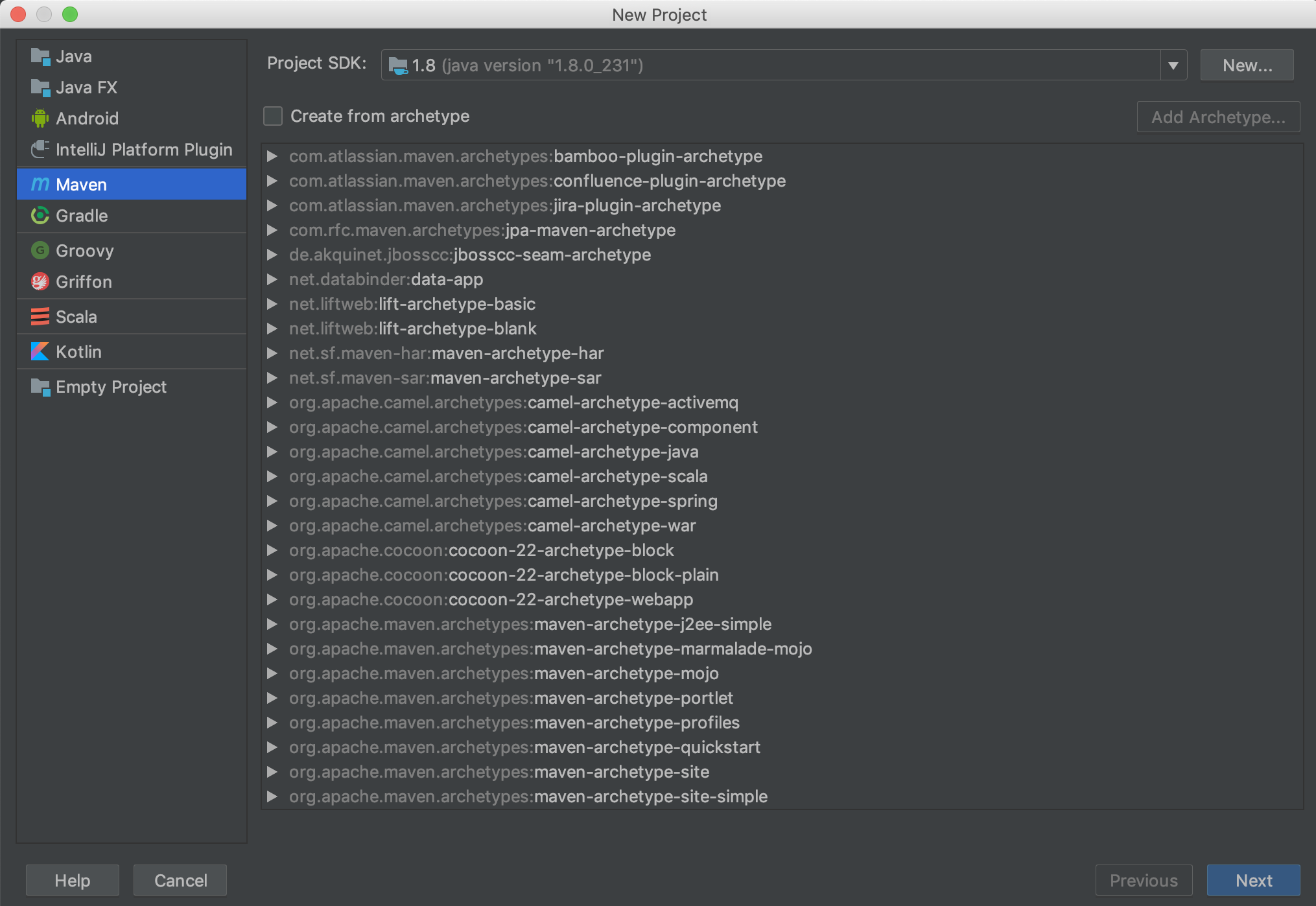
这里选择使用Maven构建项目。点击Next之后输入GroupId和ArtifactId。简单来说GroupId标识了你的组织和总的项目名称,ArtifactId标识了当前项目或子模块的名称。具体的介绍可以看一下这篇博客。
输入完GroupId和ArtifactId之后点击Next,之后输入项目的名称和位置并点击Finish即可。
新建完项目后,项目内会生成一个初始的pom文件,之后对于Spark以及其他包的依赖都会通过pom文件来完成,这里先不管它。
添加Scala SDK
因为项目中需要进行scala代码的编写,因此这里需要给项目添加Scala SDK的依赖。
点击File - Project Structure - Libraries,之后选择点击左上角的”+”号添加Scala SDK:
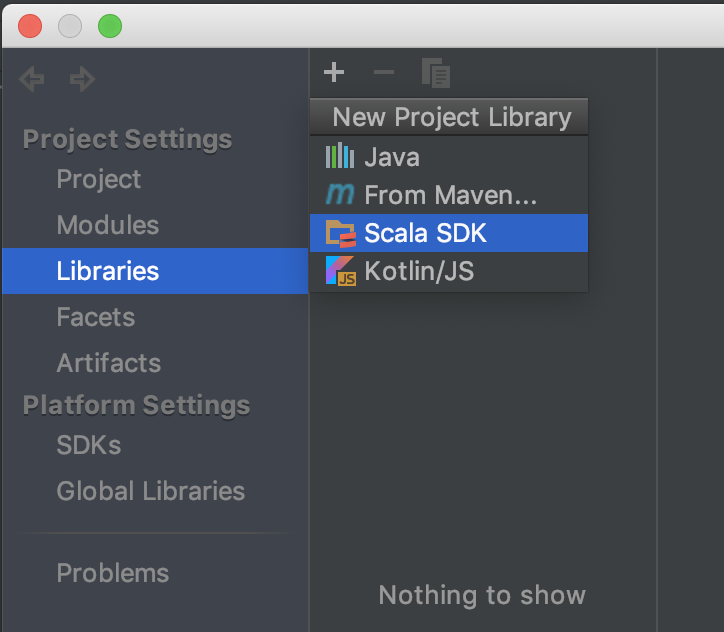
这里有两种方式,一种是点击download,选择某个版本的sdk(例如这里的2.12.4)进行下载:
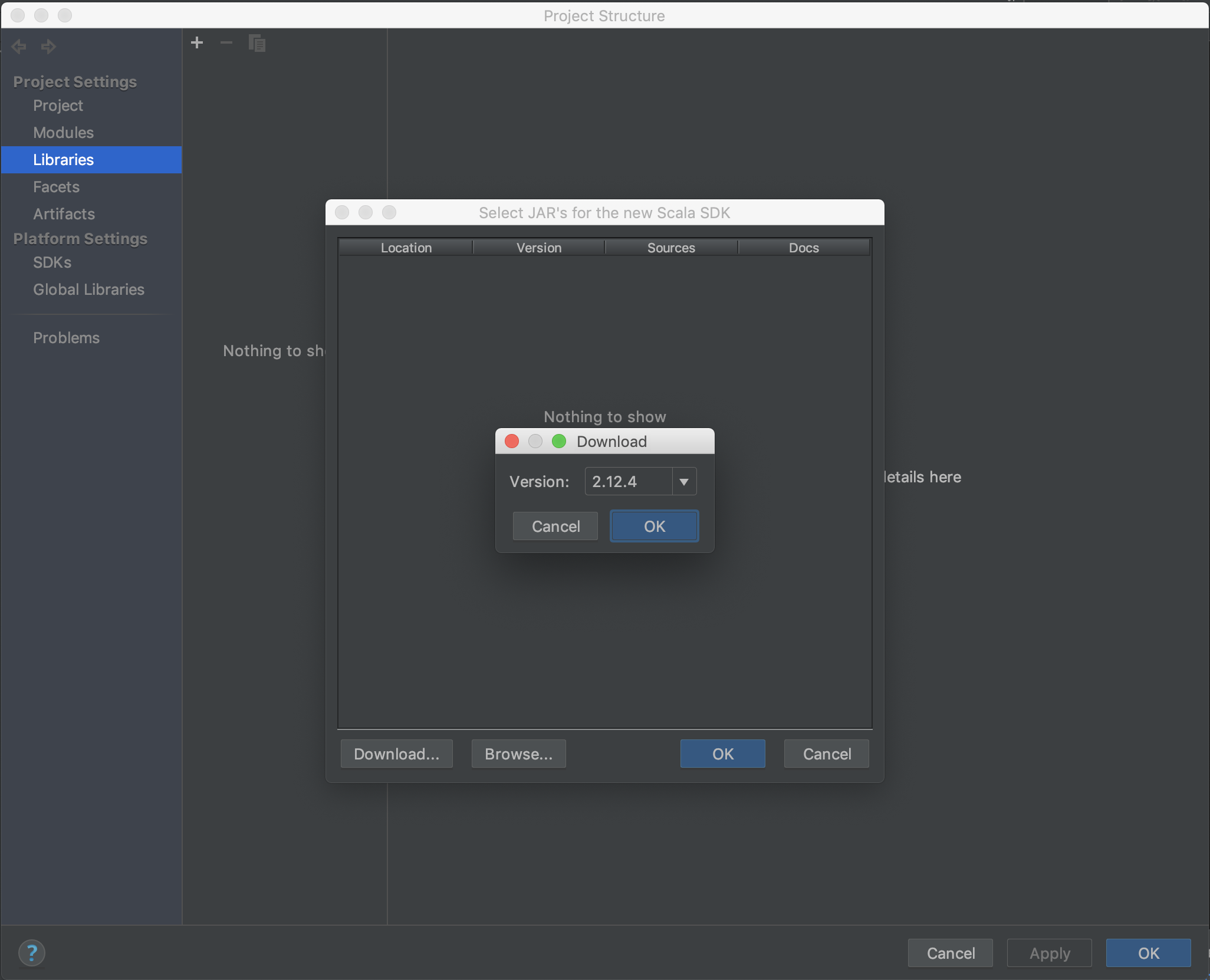
不过这种方法下载的速度非常慢,并且因为我们之前已经安装好了Scala,所以再次下载就显得没必要了。那么可以怎么做呢?其实也很简单,就是在上面那一步,不再点击download,而是点击browse,并选择自己下载的安装包解压的位置(也就是scala-2.11.12那个文件夹)。点击OK后可以看到:
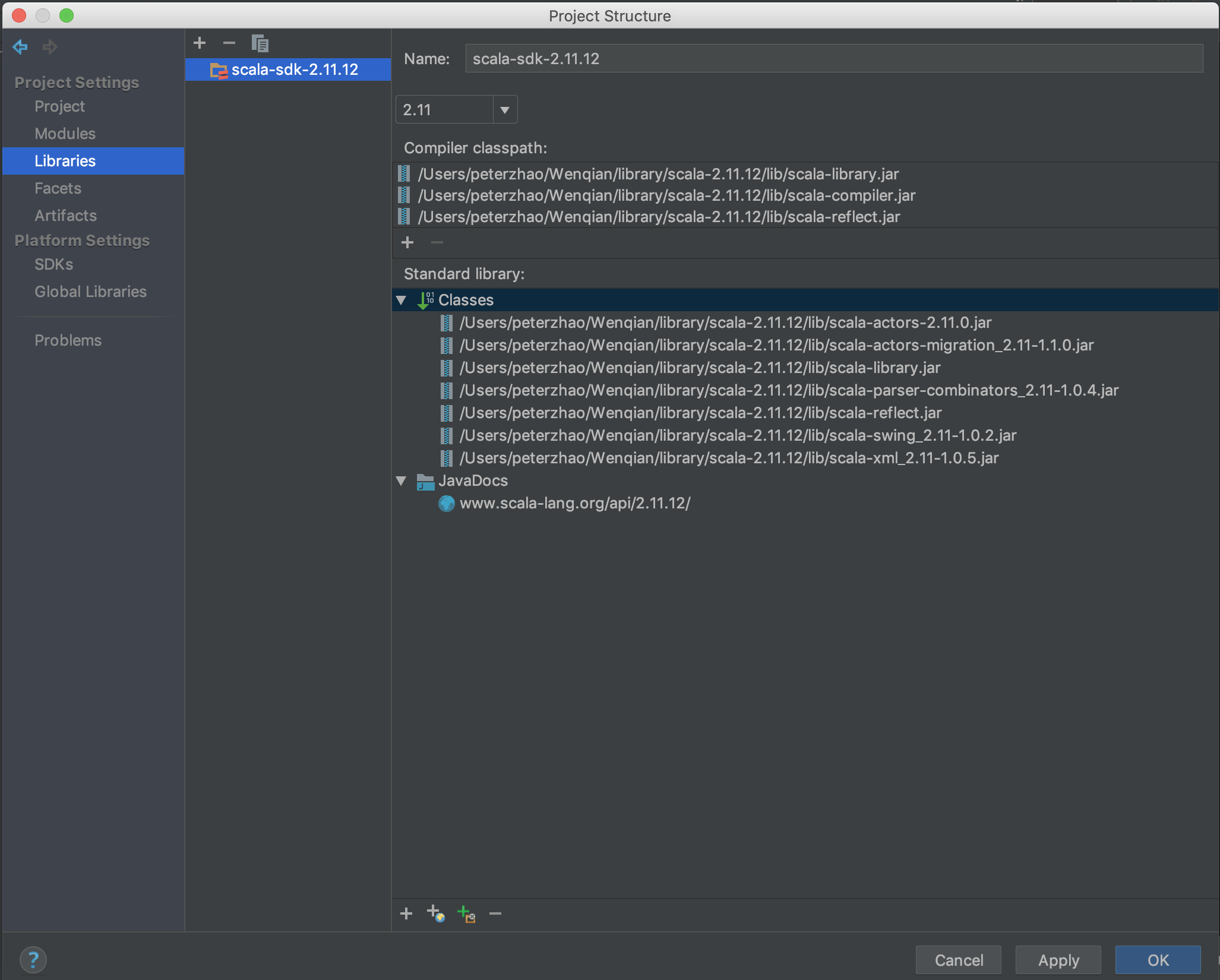
之后点击右下角的OK即可。
安装Maven
安装Maven非常方便,只要在官方网站下载好压缩包(我下载的是apache-maven-3.6.3-bin.tar.gz),然后按照官方安装文档的指示来安装即可。如果不是很清楚其中细节的,可以参考这篇博文的安装部分。
上面说的博文中有一处错误,那就是如果要使得配置文件生效需要输入:
source ~/.bash_profile,文件的位置和之前vim时是一致的。
安装完成后可以通过mvn -v语句来测试是否生效。
添加Spark依赖
打开之前说的pom文件,你应该可以看到类似于下面这样的代码:
1
2
3
4
5
6
7
8
9
10
11
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>xx.xxx.xx</groupId>
<artifactId>xx-parent</artifactId>
<version>1.0-SNAPSHOT</version>
</project>
首先对依赖的版本进行设置,采用pom里面的properties tag,其作用是声明依赖的版本信息,这样在之后的依赖中可以直接引用,将来改起来也比较好改(版本号可以根据自己的喜好修改):
1
2
3
4
5
6
7
<properties>
<java.version>1.8</java.version>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<scalatest.version>3.0.5</scalatest.version>
<spark.version>2.4.5</spark.version>
</properties>
接下来设置Maven仓库,我们这里只设置中心仓库:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<repositories>
<repository>
<id>central</id>
<!-- This should be at top, it makes maven try the central repo first and then others and hence faster dep resolution -->
<name>Maven Repository</name>
<url>https://repo1.maven.org/maven2</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<id>central</id>表示此仓库是中心仓库,关于仓库的概念和知识可以参考这篇文章。由于官方仓库的服务器并非架设在中国,因此为了速度考虑,我们可以配置仓库镜像。这里我们添加阿里云提供的镜像。
通过mvn -v中打印的内容找到Maven Home,之后在Maven Home的conf文件夹中找到settings.xml。对其进行修改,添加下面的代码(在注释mirrors的部分):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
<!-- mirrors
| This is a list of mirrors to be used in downloading artifacts from remote repositories.
|
| It works like this: a POM may declare a repository to use in resolving certain artifacts.
| However, this repository may have problems with heavy traffic at times, so people have mirrored
| it to several places.
|
| That repository definition will have a unique id, so we can create a mirror reference for that
| repository, to be used as an alternate download site. The mirror site will be the preferred
| server for that repository.
|-->
<mirrors>
<!-- mirror
| Specifies a repository mirror site to use instead of a given repository. The repository that
| this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used
| for inheritance and direct lookup purposes, and must be unique across the set of mirrors.
|
<mirror>
<id>mirrorId</id>
<mirrorOf>repositoryId</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://my.repository.com/repo/path</url>
</mirror>
-->
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<!-- https://maven.aliyun.com/repository/public/ -->
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
下面添加Spark依赖。这里用到的是Maven中的dependency tag。和dependency相关还有另一个tag,叫dependencyManagement。两者的区别可以参考这篇文章。
下面是我们要添加的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.scalatest</groupId>
<artifactId>scalatest_${scala.binary.version}</artifactId>
<version>${scalatest.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
</dependencies>
我们这里主要添加三个和spark相关的包以及两个和scala相关的包。如果想要添加其他的包,可以自行修改。
做完这些我们终于要进入到最后一步啦!(build的部分这里就不写了,有兴趣的小伙伴可以自行搜索)
写一个简单的小程序并运行
小程序的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
package org.wenqianzhao.learnspark
import org.apache.spark.sql.SparkSession
object SparkTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("SparkTest")
.master("local")
.getOrCreate()
val sc = spark.sparkContext
val result = sc.parallelize(1 to 10)
.repartition(2)
.collect()
result.foreach(println(_))
spark.stop()
}
}
代码很简单,做的事情其实就是生成一个1到10的序列,然后放入两个partition中,之后在collect到driver上,并打印出来。为了让程序能再IDEA中运行,我们需要创建一个Application。点击IDEA上方工具栏右侧的Edit Configurations:

左上角点击加号并选择Application。之后填写相关配置,主要是名称、Main Class以及Use classpath of module要写对:
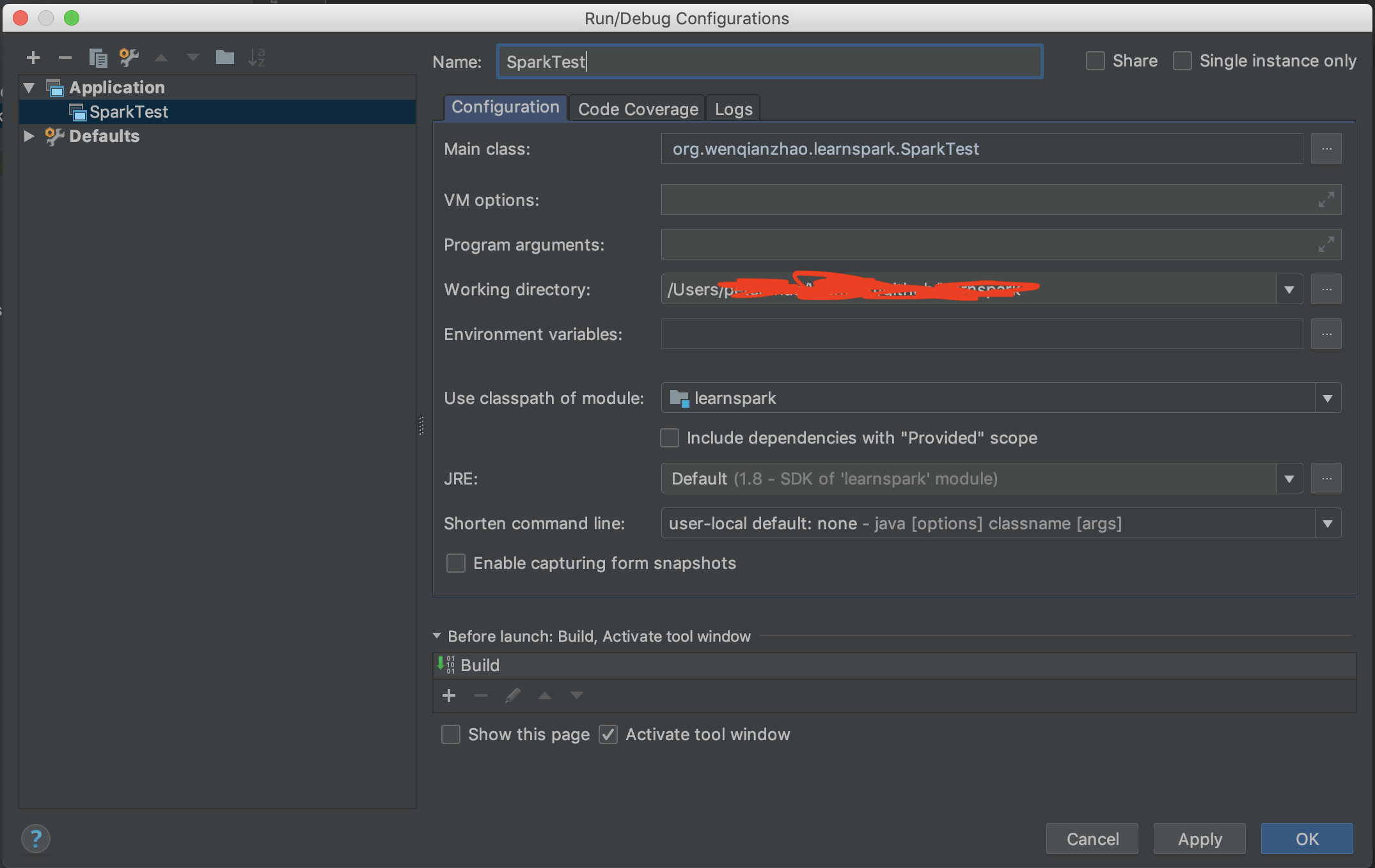
之后点击刚刚建好的配置边上的绿色三角形来运行。运行的结果如下:
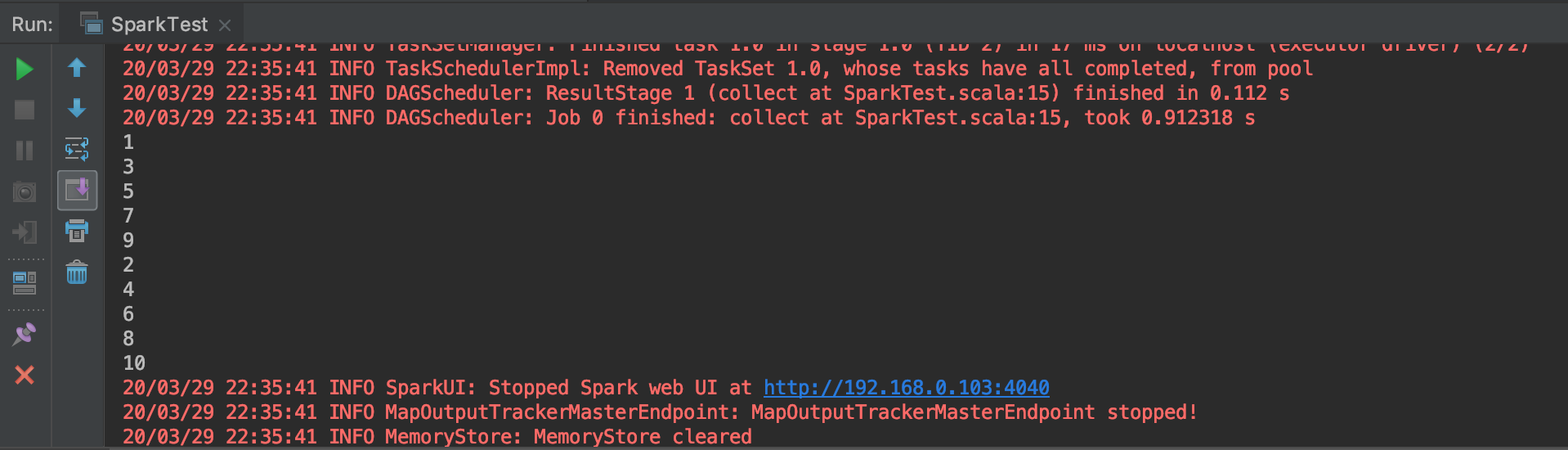
至此大功告成!观察仔细的朋友可能发现了上面那个例子打印的数字先是递增的单数,后是递增的双数,大家可以思考一下这是为什么:)